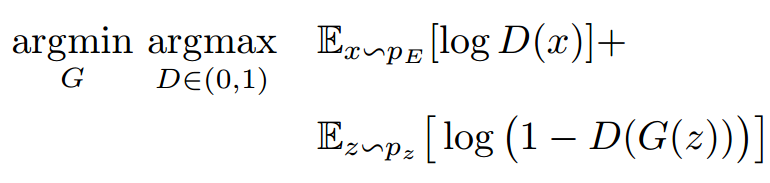
嘿,你这个叫GAIL小家伙,跟着大人学的时候,自己也要看看下一步— David 9
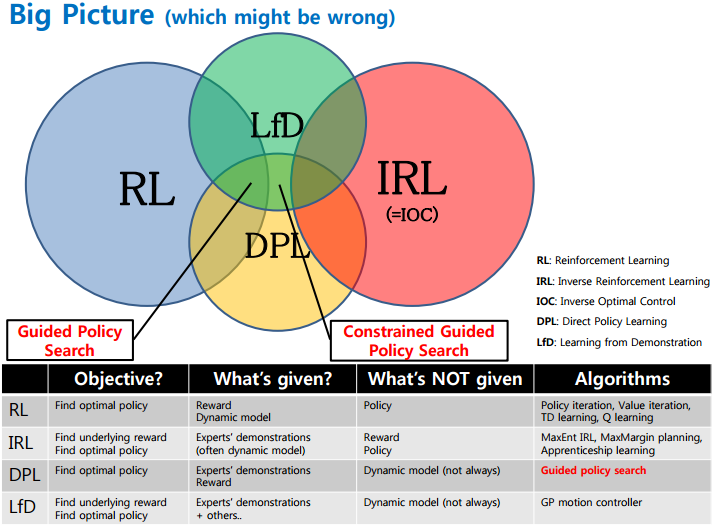
接着上次的GAIL讨论(GAN+增强学习),我们还有一个坑未填。即,基于模型的GAIL对抗模仿学习。首先回顾一下强化学习的简单体系:
1. 如果RL(强化学习)训练中给出回报(reward),其算法有我们熟悉的价值迭代value iteration算法和策略policy iteration算法,以及DPL(Direct Policy Learning假设一个policy)。
2. 如果没有明确回报(reward)给出,就涉及到更有意思的模仿学习IRL(Inverse Reinforcement Learning)。 一个实际的例子就是上次聊到的GAIL算法,简单说是假设回报函数,用GAN去识别目前的策略是否符合假设的回报函数(应有的策略):
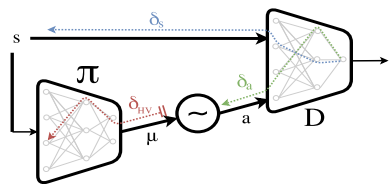
此处GAIL就产生一个问题,如上图,GAN的判别器D可以判别生成器的策略和被模仿对象(专家策略)之间的区别,但是,当把行为错误δa反向传播时,只能估算一个大概的梯度δHV 给生成器(往往不稳定并且高方差的)。这就导致一个很明显的漏洞,这个判别器D只能根据当前的行为a、被模仿者的状态x1和模仿者的状态x2做判别,如果模仿者和被模仿者像下面这样:
继续阅读端到端基于模型的GAIL对抗模仿学习,Model-based GAIL,David 9的填坑贴