“信息”技术的开垦只是刚刚开始,对于AI工作者也许更恰当的一个名称是“信息控制师” — David 9
人脑可以随时拿出一个模型处理周围信息,而不是等待别人告诉它怎么处理信息。现在所谓”深度学习”的风口,其实都只能归为信息科技。这种需要人工告诉模型如何处理信息的智能,David姑且称为“信息控制智能”。
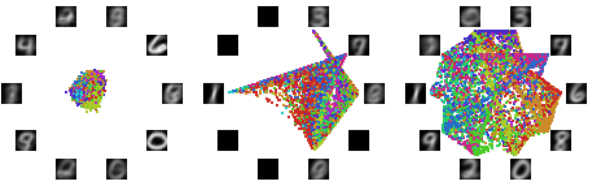
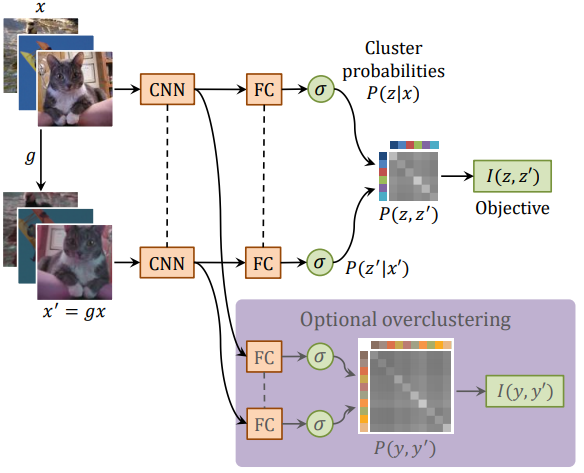
cnn做了自动的信息解构提取,rnn把时序间的信息收集提取,gan把模糊化的loss信息学习提取,包括今天要聊到的Dropout和L0正则都是对网络学到的内部信息做了控制。
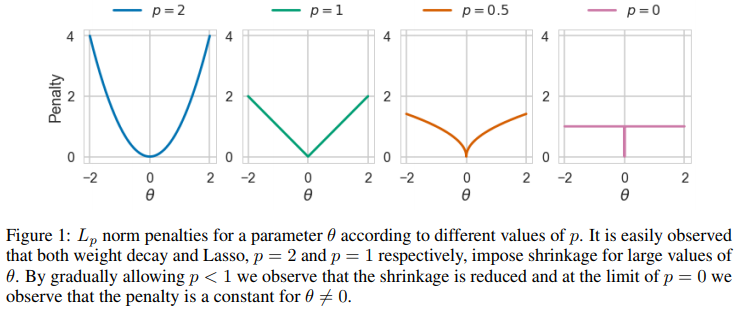
如果大家知道神经网络蒸馏、剪枝或者模型压缩和量化,大家愈发会感到:这些就是实实在在的“信息工具”而已。拿L0正则举例(其实L1, L2正则都类似),L0能做到的只是把所有的非0权重以同样的力量拉扯到0,使得网络学到的参数信息更稀疏,L1, L2不同之处只是对于不同大小的参数θ ,拉扯的力量不同而已:
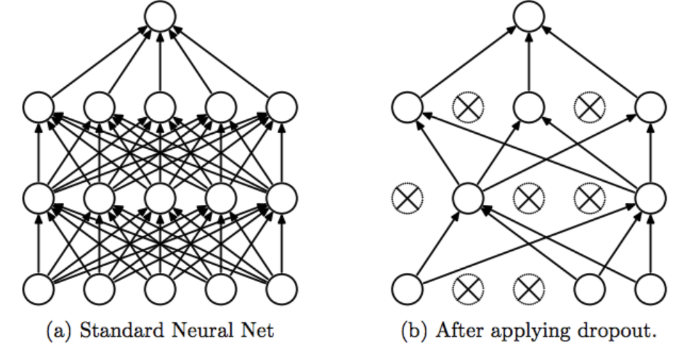
同样,for.ai与Hinton老爷子提出的定向Dropout(targeted-dropout)也可以用来压缩模型(但不丢失信息或少丢失信息)。“彩票假设”的提出者们认为,一个密集、随机初始化的前向神经网络都可以找到一个子网络(所谓的彩票),能够比较稀疏并且和原网络差别极小的性能。 继续阅读定向Dropout和L0正则,for.ai与Hinton老爷子的神经网络蒸馏、剪枝与量化新研究,稀疏化神经网络,控制参数间互信息