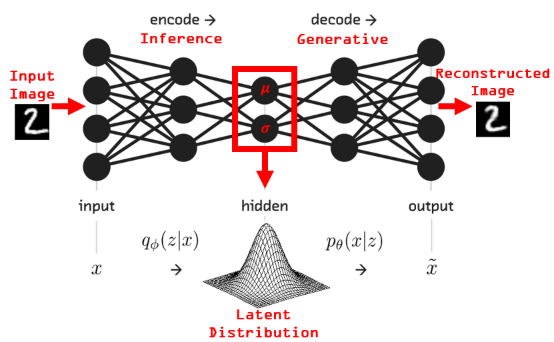
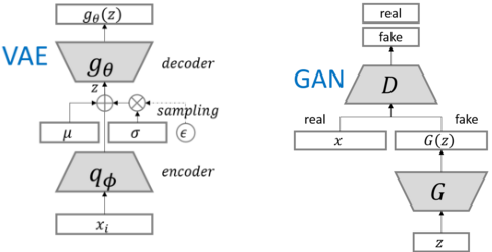
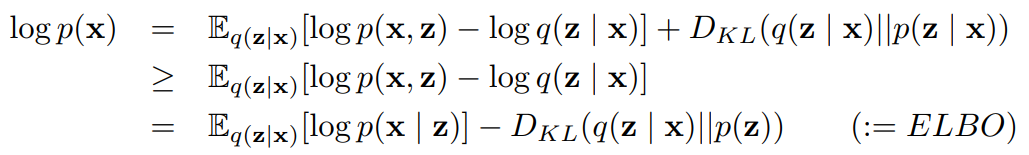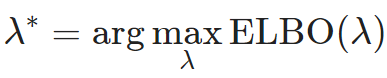一切智能体都在“噪声”中生长,甚至依赖“噪声”滋养 ,它们不是上帝,不可能在虚无中创造—— David 9
1970年,心理学家Richard Warren和他的同事研究了音素恢复在人类语言中的案例。
以“legislatures”这个单词的完整发音为例,是下图第一行的音频,如果在这段音频中切离一部分音频,替换成毫无声音的静音(第二行)音频,或替换成宽音域的噪声(第三行)音频,人类恢复声音的能力是不一样的。对于第三行的宽域噪声,人们可以很好地脑补完整的“legislatures”单词,而对于完全的静音,人们则难以“脑补”整个单词。
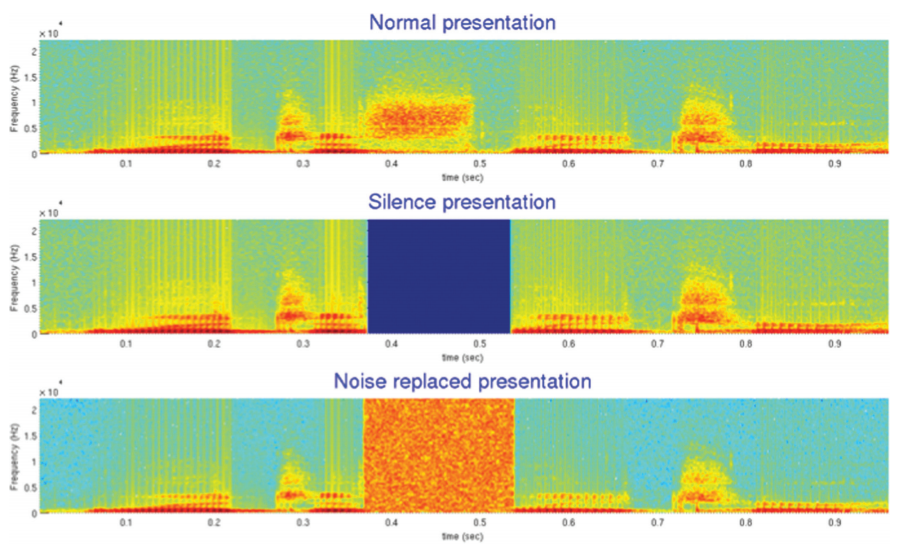
这从侧面展示噪声对智能体的作用往往被低估了,智能体善于从噪声中过滤和还原信息,而不是从虚无中。智能体善于快速地“做选择题”。
现在,借助郎之万动力学采样法,扩散生成模型(Diffusion Models) 已经可以生成高像素的人造图像,其多样性也超越了传统GAN。
其核心思想正是从噪声中一步一步还原出新图像:

而与我们 继续阅读在噪声中“生长”:扩散生成模型(Diffusion Models),score-based models,基于评分的生成模型