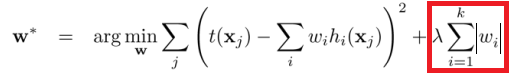
预告:
David 9 最近翻到收藏已久的链接: 卡耐基梅隆大学机器学习专业 历年最佳论文 . 其中包括3大部分:
- “经过时间考验奖”(Test of Time Awards)
- “最佳学位论文”(Dissertation Awards)
- “最佳与亚军论文奖”(Best Paper and Runner up Awards)
David 9打算就其中有意思的内容和杰出的贡献, 做几期博客分析, 敬请期待. 继续阅读系列论文分析预告—卡耐基梅隆大学 机器学习专业 历年最佳论文
David 9 最近翻到收藏已久的链接: 卡耐基梅隆大学机器学习专业 历年最佳论文 . 其中包括3大部分:
David 9打算就其中有意思的内容和杰出的贡献, 做几期博客分析, 敬请期待. 继续阅读系列论文分析预告—卡耐基梅隆大学 机器学习专业 历年最佳论文
林子大了,什么“树”都有 !
最近神经网络被学界和业界都玩坏了。之前David 9也跟风一连几篇神经网络的文章。神经网络确实到了一个新高度,其他机器学习算法在目前甚至十年以内显得黯然失色。
但是,David 9不希望大家错过其他也很棒的机器学习算法比如随机森林。虽然不如神经网络在某些领域光芒万丈,随机森林因为其方便快捷的使用,以及训练模型的简单,目前依旧深受许多数据科学家的喜爱。
如果你的老板有一堆数据,想做数据挖掘,想找一点“高大上”的算法而且容易实现,选随机森林吧。不仅比神经网络门栏低,而且对于大多数情况的数据形式,都是可以训练的。而且,有时结果好的让你惊讶。
随机森林是集成学习中的一种算法。下面这张图带大家回顾集成学习:
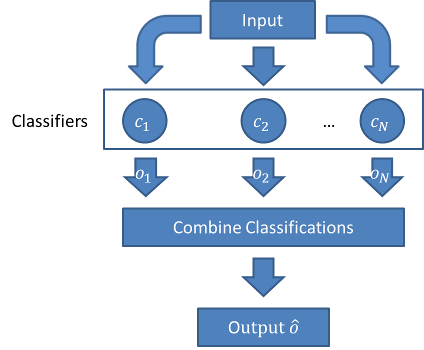
之所以叫做随机森林,很明显,这个模型是通过许多决策树集成学习而来的。集成学习是啥?如果你还不知道,请看我们之前的博客:“#3 集成学习–机器学习中的群策群力 !”和“聊聊集成学习和”多样性”, “差异性”的那些事儿~”。 继续阅读#10 随机森林101—用人话解释随机森林,用python使用随机森林
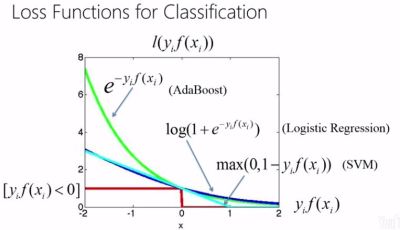
机器学习中经常会碰到“损失函数”,“成本函数”, 和“目标函数”。许多初学者会被这些概念搞晕。事实上,“损失函数”和“成本函数”在很多地方都会混用(甚至有人叫它们“错误函数”)。但是也有细微的差别。
差别1:
“损失函数”比“成本函数”更加宽泛。“损失函数”可以是一个点上的损失,也可以是整个数据集上的损失。而,“成本函数”一般是数据集上总的成本和损失。
差别2:
“成本函数”比“损失函数”更加复杂。“成本函数”可以比损失函数有更复杂的组合和计算,“成本函数”可以加上正则化项。如下: