人们已经教会计算机自动找出那些重要的特征和属性, 那么下一步我们该教会计算机什么? — David 9
用深度学习框架跑过实际问题的朋友一定有这样的感觉: 太神奇了, 它竟然能自己学习重要的特征 ! 下一步我们改教会计算机什么?莫非是教会他们寻找新的未知特征?
对于卷积神经网络cnn, 其中每个卷积核就是一个cnn习得的特征, 详见David 9之前的关于cnn博客。
今天我们的主角是keras,其简洁性和易用性简直出乎David 9我的预期。大家都知道keras是在TensorFlow上又包装了一层,向简洁易用的深度学习又迈出了坚实的一步。
所以,今天就来带大家写keras中的Hello World , 做一个手写数字识别的cnn。回顾cnn架构:
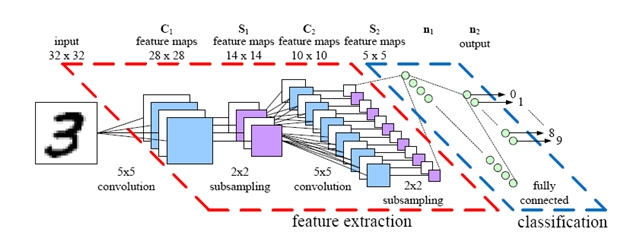
我们要处理的是这样的灰度像素图: 继续阅读keras 手把手入门#1-MNIST手写数字识别 深度学习实战闪电入门