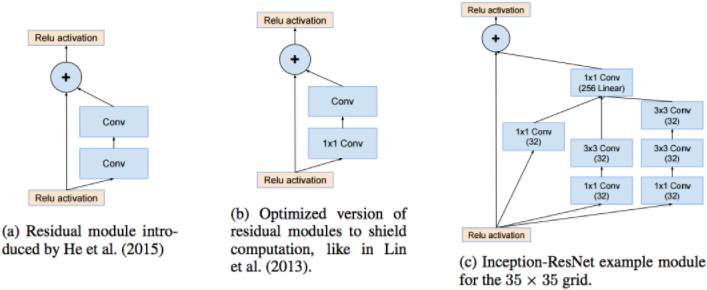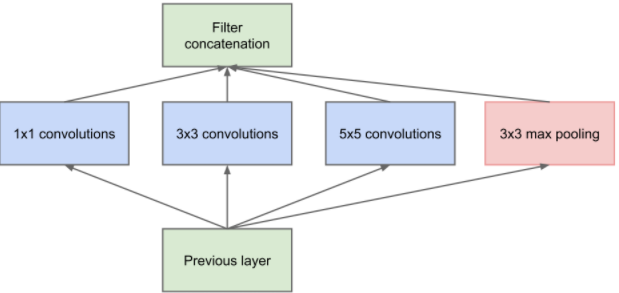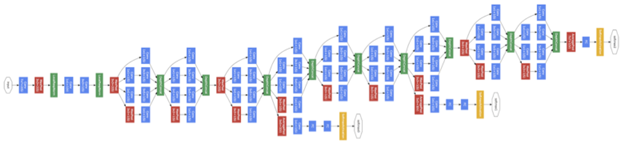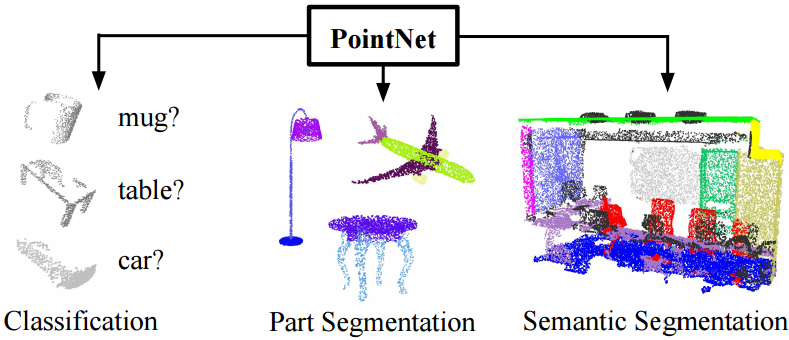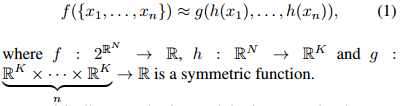
自己吹得牛逼,硬着头皮也要实现
Vicarious是和Deepmind对标的以强人工智能为目标的美国AI新兴公司。有意思的是,虽然融了上亿美元,除了工业机器人,Vicarious并没有像Deepmind的AlphaGo类似接地气的夺目产品。之前饱受争议,终于在近期公开的递归皮质网络RCN还被LeCun痛批了一回。RCN号称攻破了人类的CAPTCHA验证码自动识别,达到了神经网络300倍的数据利用率:

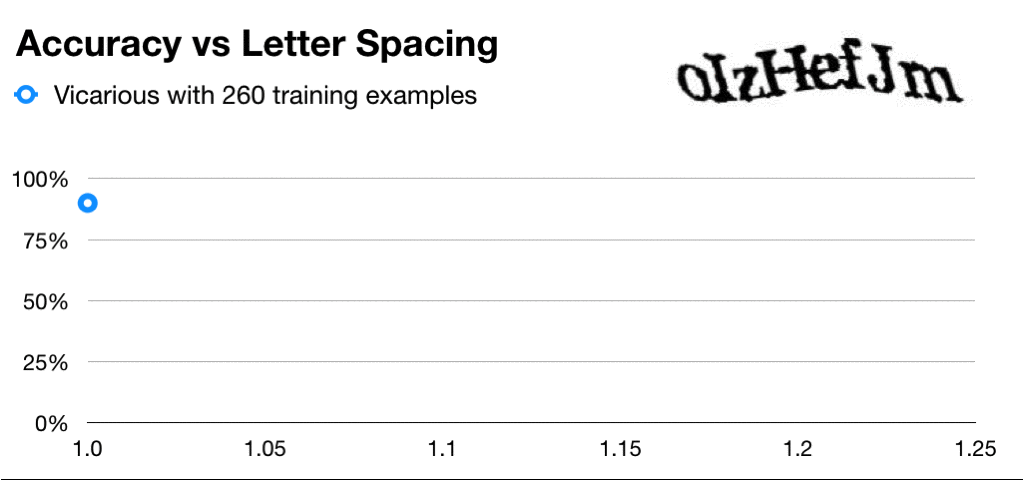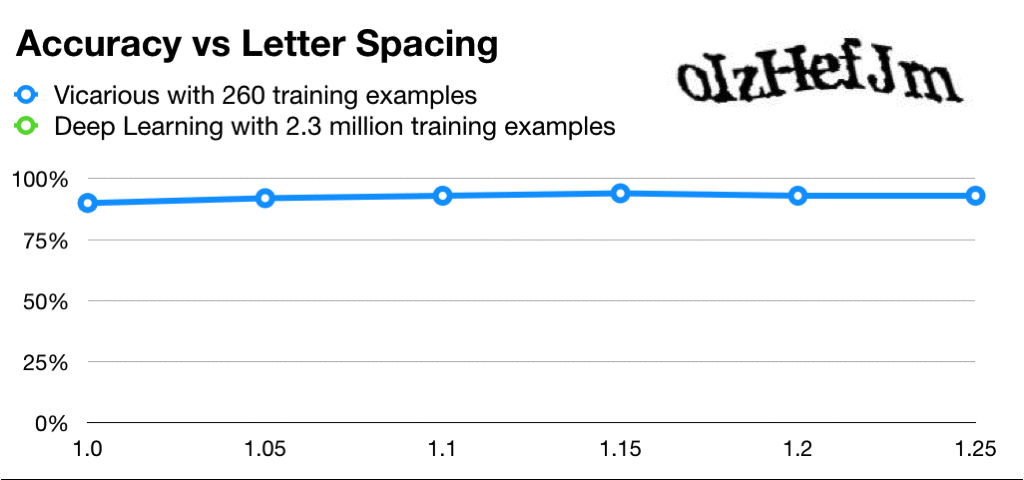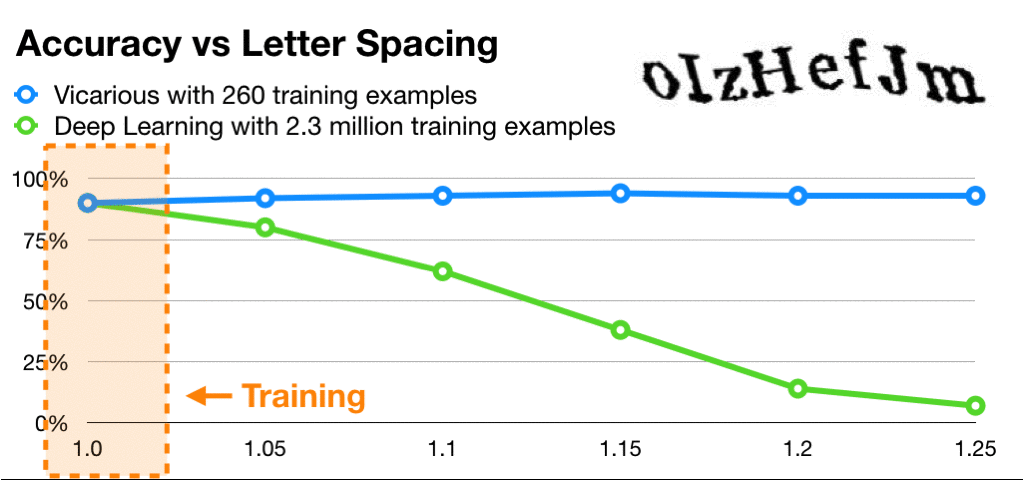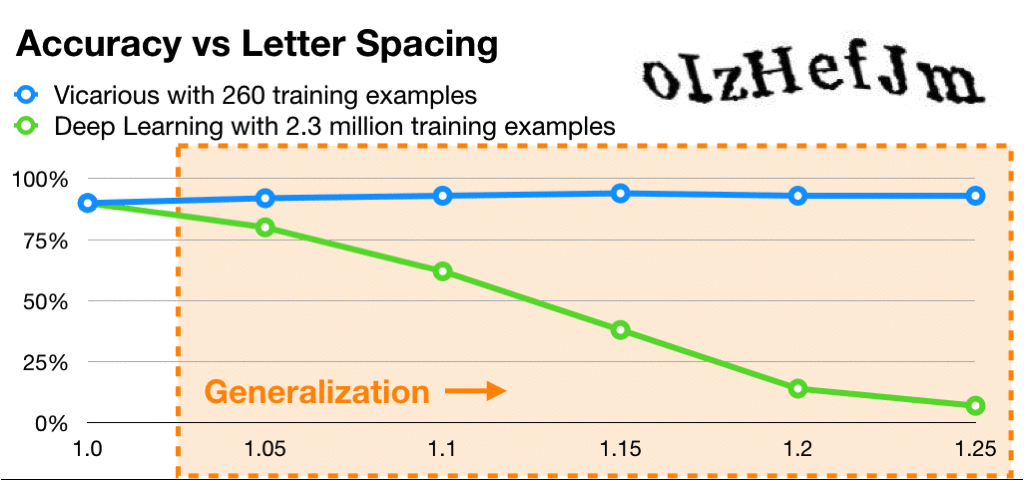
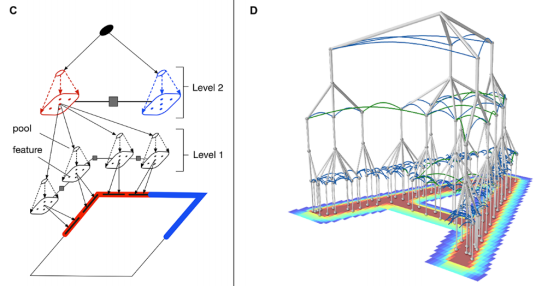
首先我们来看一下Yann LeCun早在2013年批评的理由: 继续阅读聊一聊Vicarious发表在Science的那篇生成视觉模型,被LeCun痛批的递归皮质网络RCN