藏私房钱的男同胞们, 是不是先要把钱分好几份, 然后藏在房间中的不同位置 ? 现在, 这种”智慧”用在了数据隐私上 … —— David 9
虽然本届ICLR有许多不公平的评审传言, 但是令人欣慰的是, 目前深度学习发展如此迅猛, 以至于一些好的理论文章没有通过评审, 而有用的实际应用文章又如此之多让评审员为难. 无论如何, 今天要讲的这篇论文在保护训练隐私数据上非常有用, 从而浮出水面.
这篇论文也出自Google 大脑之手, 名为: SEMI-SUPERVISED KNOWLEDGE TRANSFER FOR DEEP LEARNING FROM PRIVATE TRAINING DATA. 论文给出了一种通用性的训练隐私数据的解决方案,名为”「教师」集成模型的隐私聚合”(Private Aggregation of Teacher Ensembles/PATE),PATE 发音类似”法国肉酱”这种食物。

框架总览:
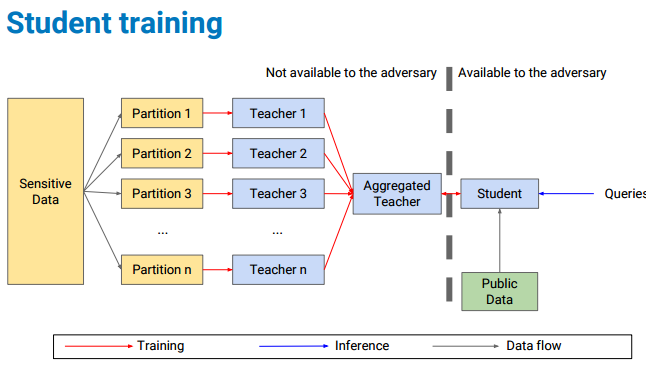
目前对于模型隐私数据的攻击威胁一般基于以下两个假设: 继续阅读ICLR 2017论文精选#2—用半监督知识迁移增强深度学习中训练数据的隐私(Best paper award 最佳论文奖)