当深度网络应用在增强学习中,人们发现一些训练的捷径,但是没有统一的看法。每当深度网络应用在一个领域,总是会重复类似的故事,这也许正是深度学习有意思的地方 — David 9
如果你想入深度增强学习的坑,你一定发现在增强学习domain下,深度网络构建有那么多技巧。
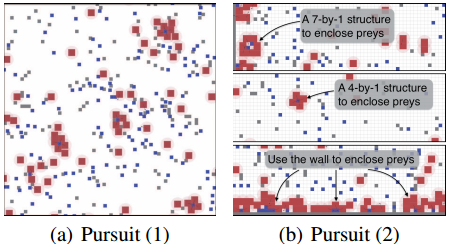
不像一般的机器视觉,深度网络在增强学习中被用来理解环境(states)和回报值(reward),最终输出一个行为策略。
因此关注的最小粒度其实是行为(action),依旧使用传统梯度下降更新网络并不高效(行为的跳跃很大,梯度更新可能很小)。另外,增强学习其实是可以高并行的问题,试想如果你有很多分身去玩Dota,最后让他们把关键经验告诉你,就省去了很多功夫。
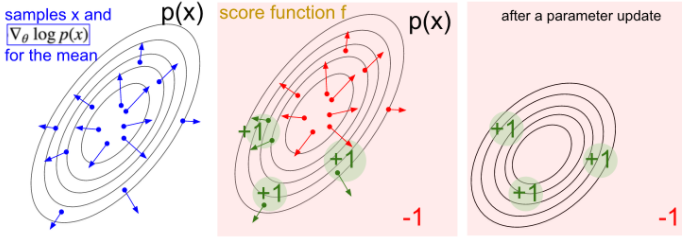
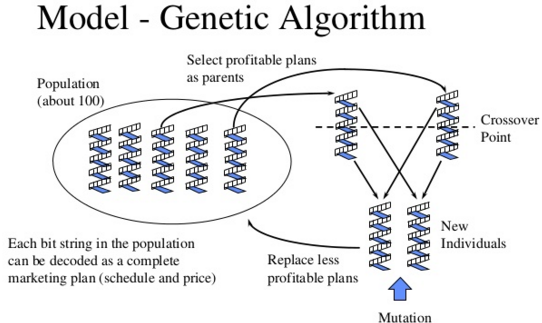
在经验和行为主导的增强学习背景下,催生了DQN,A3C,Evolution Strategies等一系列深度网络的训练方法。包括我们今天的主角:遗传算法(GA)。
Uber AI实验室发现GA对行为策略的把控,可以结合到深度网络中,他们称之为深度神经进化(Deep Neuroevolution),在某些领域的表现甚至超过了DQN,A3C,Evolution Strategies。 继续阅读深度神经进化,Uber AI实验室新发现:遗传算法(GA)在深度增强学习中的出色表现(Deep Neuroevolution)