Since the initial standpoint of science, technology and AI, scientists following Blaise Pascal and Von Leibniz ponder about a machine that is intellectually capable as much as humans. Famous writers like Jules

Machine Learning is one of the important lanes of AI which is very spicy hot subject in the research or industry. Companies, universities devote many resources to advance their knowledge. Recent advances in the field propel very solid results for different tasks, comparable to human performance (98.98% at Traffic Signs – higher than human-).
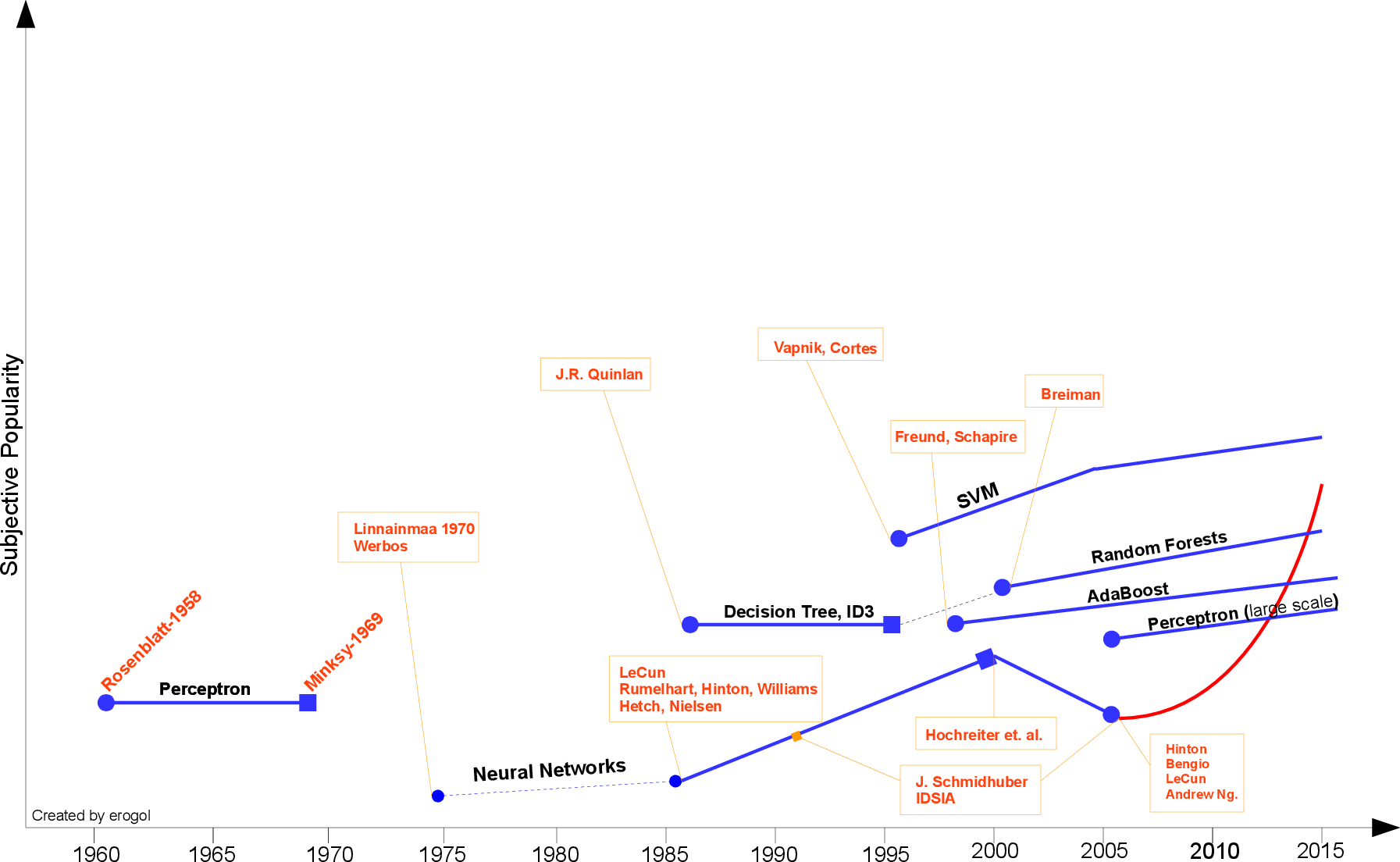
Here I would like to share a crude timeline of Machine Learning and sign some of the milestones by no means complete. In addition, you should add “up to my knowledge” to beginning of any argument in the text.
First step toward prevalent ML was proposed by Hebb , in 1949, based on a neuropsychological learning formulation. It is called Hebbian Learning theory. With a simple explanation, it pursues correlations between nodes of a Recurrent Neural Network (RNN). It memorizes any commonalities on the network and serves like a memory later. Formally, the argument states that;
Let us assume that the persistence or repetition of a reverberatory activity (or “trace”) tends to induce lasting cellular changes that add to its stability.… When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased.[1]

In 1952 , Arthur Samuel at IBM, developed a program playing Checkers . The program was able to observe positions and learn a implicit model that gives better moves for the latter cases. Samuel played so many games with the program and observed that the program was able to play better in the course of time.
With that program Samuel confuted the general providence dictating machines cannot go beyond the written codes and learn patterns like human-beings. He coined “machine learning, ” which he defines as;
a field of study that gives computer the ability without being explicitly programmed.

In 1957 , Rosenblatt’s Perceptron was the second model proposed again with neuroscientific background and it is more similar to today’s ML models. It was a very exciting discovery at the time and it was practically more applicable than Hebbian’s idea. Rosenblatt introduced the Perceptron with the following lines;
The perceptron is designed to illustrate some of the fundamental properties of intelligent systems in general, without becoming too deeply enmeshed in the special, and frequently unknown, conditions which hold for particular biological organisms.[2]
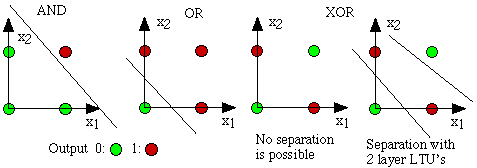
After 3 years later, Widrow [4] engraved Delta Learning rule that is then used as practical procedure for Perceptron training. It is also known as Least Square problem. Combination of those two ideas creates a good linear classifier. However, Perceptron’s excitement was hinged by Minsky [3] in 1969 . He proposed the famousXOR problem and the inability of Perceptrons in such linearly inseparable data distributions. It was the Minsky’s tackle to NN community. Thereafter, NN researches would be dormant up until 1980s
There had been not to much effort until the intuition of Multi-Layer Perceptron (MLP) was suggested byWerbos[6] in 1981 with NN specific Backpropagation(BP) algorithm, albeit BP idea had been proposed before by Linnainmaa [5] in 1970 in the name “reverse mode of automatic differentiation”. Still BP is the key ingredient of today’s NN architectures. With those new ideas, NN researches accelerated again. In 1985 – 1986 NN researchers successively presented the idea of MLP with practical BP training (Rumelhart, Hinton, Williams [7] – Hetch, Nielsen[8])
![From Hetch and Nielsen [8]](https://nooverfit.com/wp/wp-content/uploads/2016/05/fdba4d2ea52a384c933405ba78bb4292.png)
After ID3, many different alternatives or improvements have been explored by the community (e.g. ID4, Regression Trees, CART …) and still it is one of the active topic in ML.
![From Quinlan [9]](https://nooverfit.com/wp/wp-content/uploads/2016/05/51e4f88f3e218020c6d0883886192e9d.png)
![Vapnik and Cortes [10]](https://nooverfit.com/wp/wp-content/uploads/2016/05/f96c032b2e6811a1fdb5e92809ec1fec.png)
Little before, another solid ML model was proposed by Freund and Schapire in 1997 prescribed with boosted ensemble of weak classifiers called Adaboost. This work also gave the Godel Prize to the authors at the time. Adaboost trains weak set of classifiers that are easy to train, by giving more importance to hard instances. This model still the basis of many different tasks like face recognition and detection. It is also a realization of PAC (Probably Approximately Correct) learning theory. In general, so called weak classifiers are chosen as simple decision stumps (single decision tree nodes). They introduced Adaboost as ;
The model we study can be interpreted as a broad, abstract extension of the well-studied on-line prediction model to a general decision-theoretic setting…[11]
Another ensemble model explored by Breiman [12] in 2001 that ensembles multiple decision trees where each of them is curated by a random subset of instances and each node is selected from a random subset of features. Owing to its nature, it is called Random Forests(RF) . RF has also theoretical and empirical proofs of endurance against over-fitting. Even AdaBoost shows weakness to over-fitting and outlier instances in the data, RF is more robust model against these caveats.(For more detail about RF, refer tomy old post.). RF shows its success in many different tasks like Kaggle competitions as well.
Random forests are a combination of tree predictors such that each tree depends on the values of a
random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large[12]
As we come closer today, a new era of NN called Deep Learning has been commerced. This phrase simply refers NN models with many wide successive layers. The 3rd rise of NN has begun roughly in 2005 with the conjunction of many different discoveries from past and present by recent mavens Hinton, LeCun, Bengio, Andrew Ng and other valuable older researchers. I enlisted some of the important headings (I guess, I will dedicate complete post for Deep Learning specifically) ;
- GPU programming
- Convolutional NNs [18][20][40]
- Deconvolutional Networks [21]
- Optimization algorithms
- Stochastic Gradient Descent [19][22]
- BFGS and L-BFGS [23]
- Conjugate Gradient Descent [24]
- Backpropagation [40][19]
- Rectifier Units
- Sparsity [15][16]
- Dropout Nets [26]
- Maxout Nets [25]
- Unsupervised NN models [14]
- Deep Belief Networks [13]
- Stacked Auto-Encoders [16][39]
- Denoising NN models [17]
With the combination of all those ideas and non-listed ones, NN models are able to beat off state of art at very different tasks such as Object Recognition, Speech Recognition, NLP etc. However, it should be noted that this absolutely does not mean, it is the end of other ML streams. Even Deep Learning success stories grow rapidly , there are many critics directed to training cost and tuning exogenous parameters of these models. Moreover, still SVM is being used more commonly owing to its simplicity. (said but may cause a huge debate  )
)
Before finish, I need to touch on one another relatively young ML trend. After the growth of WWW and Social Media, a new term, BigData emerged and affected ML research wildly. Because of the large problems arising from BigData , many strong ML algorithms are useless for reasonable systems (not for giant Tech Companies of course). Hence, research people come up with a new set of simple models that are dubbed Bandit Algorithms [27 – 38] (formally predicated with Online Learning ) that makes learning easier and adaptable for large scale problems.
I would like to conclude this infant sheet of ML history. If you found something wrong (you should ), insufficient or non-referenced, please don’t hesitate to warn me in all manner.
References —-
[1] Hebb D. O., The organization of behaviour. New York: Wiley & Sons.
[2] Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
[3] Minsky, Marvin, and Papert Seymour. “Perceptrons.” (1969).
[4]Widrow, Hoff “Adaptive switching circuits.” (1960): 96-104.
[5]S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor
expansion of the local rounding errors. Master’s thesis, Univ. Helsinki, 1970.
[6] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In Proceedings of the 10th
IFIP Conference, 31.8 – 4.9, NYC, pages 762–770, 1981.
[7] Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by error propagation. No. ICS-8506. CALIFORNIA UNIV SAN DIEGO LA JOLLA INST FOR COGNITIVE SCIENCE, 1985.
[8] Hecht-Nielsen, Robert. “Theory of the backpropagation neural network.” Neural Networks, 1989. IJCNN., International Joint Conference on. IEEE, 1989.
[9] Quinlan, J. Ross. “Induction of decision trees.” Machine learning 1.1 (1986): 81-106.
[10] Cortes, Corinna, and Vladimir Vapnik. “Support-vector networks.” Machine learning 20.3 (1995): 273-297.
[11] Freund, Yoav, Robert Schapire, and N. Abe. “A short introduction to boosting.” Journal-Japanese Society For Artificial Intelligence 14.771-780 (1999): 1612.
[12] Breiman, Leo. “Random forests.” Machine learning 45.1 (2001): 5-32.
[13] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. “A fast learning algorithm for deep belief nets.” Neural computation 18.7 (2006): 1527-1554.
[14] Bengio, Lamblin, Popovici, Larochelle, “Greedy Layer-Wise
Training of Deep Networks”, NIPS’2006
[15] Ranzato, Poultney, Chopra, LeCun ” Efficient Learning of Sparse Representations with an Energy-Based Model “, NIPS’2006
[16] Olshausen B a, Field DJ. Sparse coding with an overcomplete basis set: a strategy employed by V1? Vision Res. 1997;37(23):3311–25. Available at: http://www.ncbi.nlm.nih.gov/pubmed/9425546.
[17] Vincent, H. Larochelle Y. Bengio and P.A. Manzagol, Extracting and Composing Robust Features with Denoising Autoencoders , Proceedings of the Twenty-fifth International Conference on Machine Learning (ICML‘08), pages 1096 – 1103, ACM, 2008.
[18] Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36, 193–202.
[19] LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.
[20] LeCun, Yann, and Yoshua Bengio. “Convolutional networks for images, speech, and time series.” The handbook of brain theory and neural networks3361 (1995).
[21] Zeiler, Matthew D., et al. “Deconvolutional networks.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
[22] S. Vishwanathan, N. Schraudolph, M. Schmidt, and K. Mur- phy. Accelerated training of conditional random fields with stochastic meta-descent. In International Conference on Ma- chine Learning (ICML ’06), 2006.
[23] Nocedal, J. (1980). ”Updating Quasi-Newton Matrices with Limited Storage.” Mathematics of Computation 35 (151): 773782. doi:10.1090/S0025-5718-1980-0572855-
[24] S. Yun and K.-C. Toh, “A coordinate gradient descent method for l1- regularized convex minimization,” Computational Optimizations and Applications, vol. 48, no. 2, pp. 273–307, 2011.
[25] Goodfellow I, Warde-Farley D. Maxout networks. arXiv Prepr arXiv …. 2013. Available at: http://arxiv.org/abs/1302.4389. Accessed March 20, 2014.
[26] Wan L, Zeiler M. Regularization of neural networks using dropconnect. Proc …. 2013;(1). Available at: http://machinelearning.wustl.edu/mlpapers/papers/icml2013_wan13. Accessed March 13, 2014.
[27] Alekh Agarwal , Olivier Chapelle , Miroslav Dudik , John Langford , A Reliable Effective Terascale Linear Learning System , 2011
[28] M. Hoffman , D. Blei , F. Bach , Online Learning for Latent Dirichlet Allocation , in Neural Information Processing Systems (NIPS) 2010.
[29] Alina Beygelzimer , Daniel Hsu , John Langford , and Tong Zhang Agnostic Active Learning Without Constraints NIPS 2010.
[30] John Duchi , Elad Hazan , and Yoram Singer , Adaptive Subgradient Methods for Online Learning and Stochastic Optimization , JMLR 2011 & COLT 2010.
[31] H. Brendan McMahan , Matthew Streeter , Adaptive Bound Optimization for Online Convex Optimization , COLT 2010.
[32] Nikos Karampatziakis and John Langford , Importance Weight Aware Gradient Updates UAI 2010.
[33] Kilian Weinberger , Anirban Dasgupta , John Langford , Alex Smola , Josh Attenberg , Feature Hashing for Large Scale Multitask Learning , ICML 2009.
[34] Qinfeng Shi , James Petterson , Gideon Dror , John Langford , Alex Smola , and SVN Vishwanathan , Hash Kernels for Structured Data , AISTAT 2009.
[35] John Langford , Lihong Li , and Tong Zhang , Sparse Online Learning via Truncated Gradient , NIPS 2008.
[36] Leon Bottou , Stochastic Gradient Descent , 2007.
[37] Avrim Blum , Adam Kalai , and John Langford Beating the Holdout: Bounds for KFold and Progressive Cross-Validation . COLT99 pages 203-208.
[38] Nocedal, J. (1980). “Updating Quasi-Newton Matrices with Limited Storage”. Mathematics of Computation 35: 773–782.
[39] D. H. Ballard. Modular learning in neural networks. In AAAI, pages 279–284, 1987.
[40] S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut f ̈ur In-
formatik, Lehrstuhl Prof. Brauer, Technische Universit ̈at M ̈unchen, 1991. Advisor: J. Schmidhuber.
David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
Great, yahoo took me stright here. thanks btw for this. Cheers!