2018也许是AutoML(自动化机器学习)的探索元年。就让我们从AutoML聊起。
1. AdaNet — 一个基于TensorFlow的开源神经网络自动学习项目。
也许你之前听过Auto-Keras 和 Auto-Sklearn ,但是如果要认真去做神经网络的AutoML,AdaNet 有许多值得借鉴的地方。
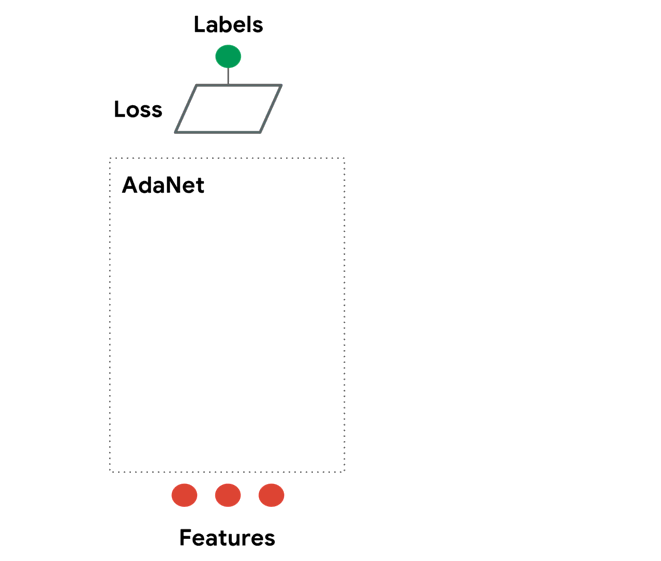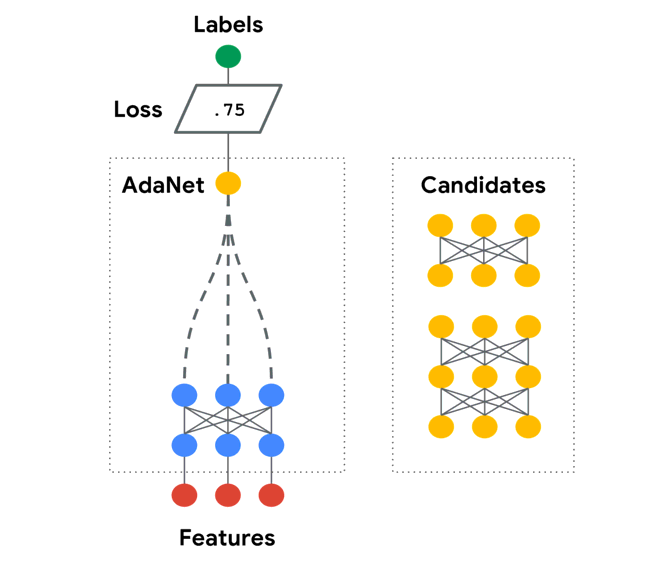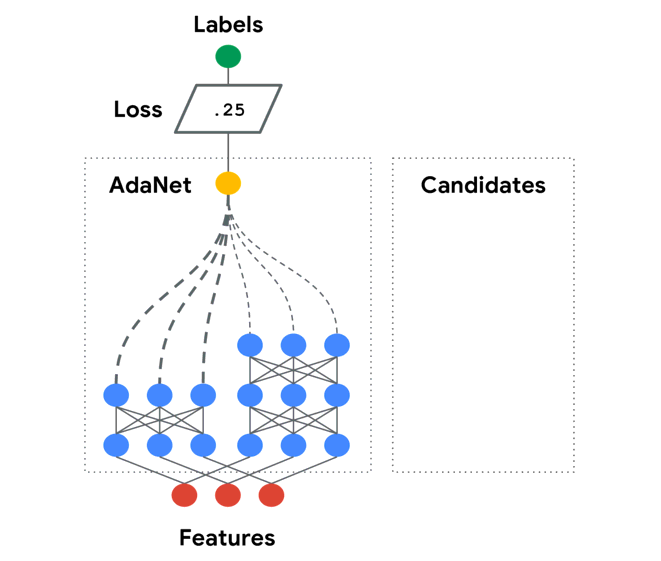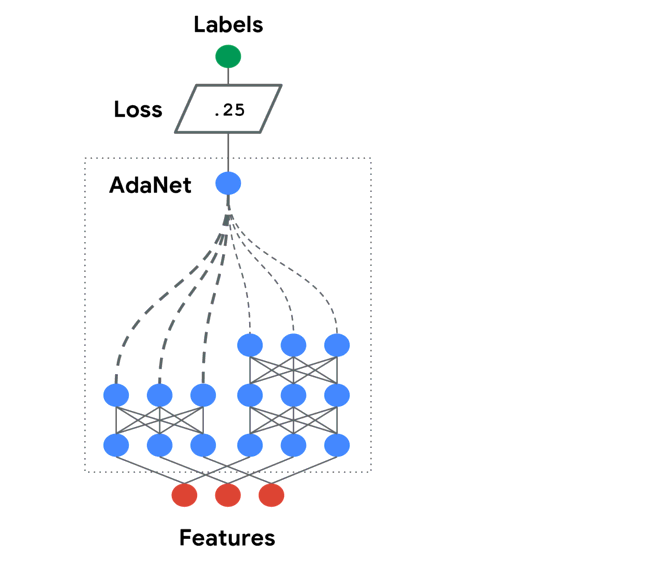
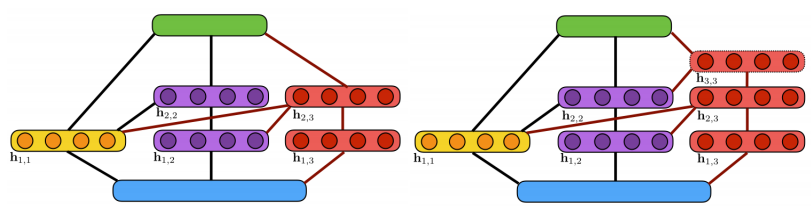
如上图,AdaNet会在网络层中尝试使用不用的候选(Candidates)结构和参数。并且自己维护一个Adanet loss(带正则):
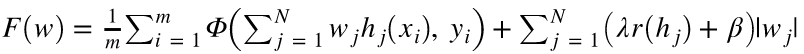
入门AdaNet 可以先通读项目中的例程:https://github.com/tensorflow/adanet/blob/master/adanet/examples/tutorials/adanet_objective.ipynb ,并理解如何使用AdaNet已有类构造子网络生成器:
class SimpleDNNGenerator(adanet.subnetwork.Generator):
"""Generates a two DNN subnetworks at each iteration.
The first DNN has an identical shape to the most recently added subnetwork
in `previous_ensemble`. The second has the same shape plus one more dense
layer on top. This is similar to the adaptive network presented in Figure 2 of
[Cortes et al. ICML 2017](https://arxiv.org/abs/1607.01097), without the
connections to hidden layers of networks from previous iterations.
"""
def __init__(self,
optimizer,
layer_size=64,
learn_mixture_weights=False,
seed=None):
"""Initializes a DNN `Generator`.
Args:
optimizer: An `Optimizer` instance for training both the subnetwork and
the mixture weights.
layer_size: Number of nodes in each hidden layer of the subnetwork
candidates. Note that this parameter is ignored in a DNN with no hidden
layers.
learn_mixture_weights: Whether to solve a learning problem to find the
best mixture weights, or use their default value according to the
mixture weight type. When `False`, the subnetworks will return a no_op
for the mixture weight train op.
seed: A random seed.
Returns:
An instance of `Generator`.
"""
self._seed = seed
self._dnn_builder_fn = functools.partial(
_SimpleDNNBuilder,
optimizer=optimizer,
layer_size=layer_size,
learn_mixture_weights=learn_mixture_weights)
def generate_candidates(self, previous_ensemble, iteration_number,
previous_ensemble_reports, all_reports):
"""See `adanet.subnetwork.Generator`."""
num_layers = 0
seed = self._seed
if previous_ensemble:
num_layers = tf.contrib.util.constant_value(
previous_ensemble.weighted_subnetworks[
-1].subnetwork.persisted_tensors[_NUM_LAYERS_KEY])
if seed is not None:
seed += iteration_number
return [
self._dnn_builder_fn(num_layers=num_layers, seed=seed),
self._dnn_builder_fn(num_layers=num_layers + 1, seed=seed),
]
2. TPOT — 贴心到要把特征选择、模型选择和模型优化一并做了
TPOT试图把繁琐的 特征选择、模型选择和模型优化 一并做优化并输出在另一个py文件中:
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_mnist_pipeline.py')
运行以上代码会自动优化并输出
tpot_mnist_pipeline.py 代码文件:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# NOTE: Make sure that the class is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1).values
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'].values, random_state=None)
exported_pipeline = KNeighborsClassifier(n_neighbors=6, weights="distance")
exported_pipeline.fit(training_features, training_classes)
results = exported_pipeline.predict(testing_features)
但是tpot基于scikit-learn,如果没有进行很高的优化,代码运行时间可能会令你无法忍受。其使用简单到是适合初学者实验。
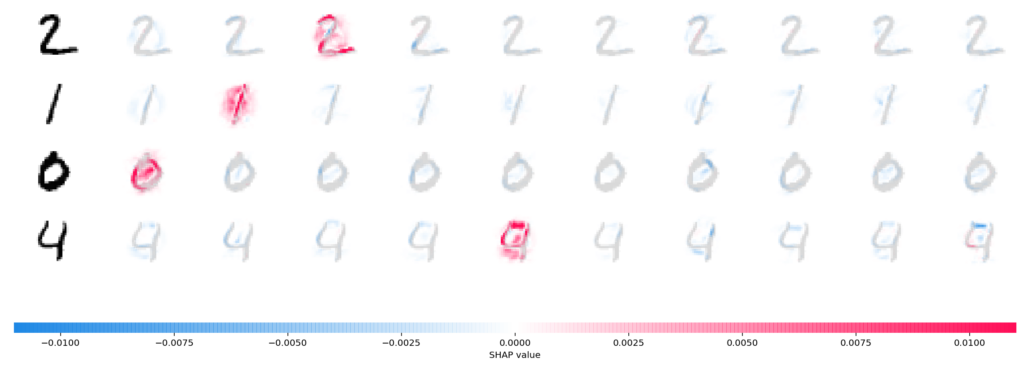
3. SHAP — 解释模型的预测行为
SHAP比一般模型分析工具好用的地方有两个,
- 支持tensorflow,pytorch,keras等深度学习框架
- 支持深度神经网络模型的预测行为可视化,如下图,红色的像素区域表示在当前标签下的概率更大:

只需短短几行代码你就可以生成数据增强图片:
p = Augmentor.Pipeline("/path/to/images")
# Point to a directory containing ground truth data.
# Images with the same file names will be added as ground truth data
# and augmented in parallel to the original data.
p.ground_truth("/path/to/ground_truth_images")
# Add operations to the pipeline as normal:
p.rotate(probability=1, max_left_rotation=5, max_right_rotation=5)
p.flip_left_right(probability=0.5)
p.zoom_random(probability=0.5, percentage_area=0.8)
p.flip_top_bottom(probability=0.5)
p.sample(50)
Augmentor还支持加入图片噪声和图像扭曲等功能:


2018年不乏许多好的自然语言项目,spaCy就是其中之一。spaCy 使用较新的研究成果作出产品级别的功能,包含的feature不限于以下所列:
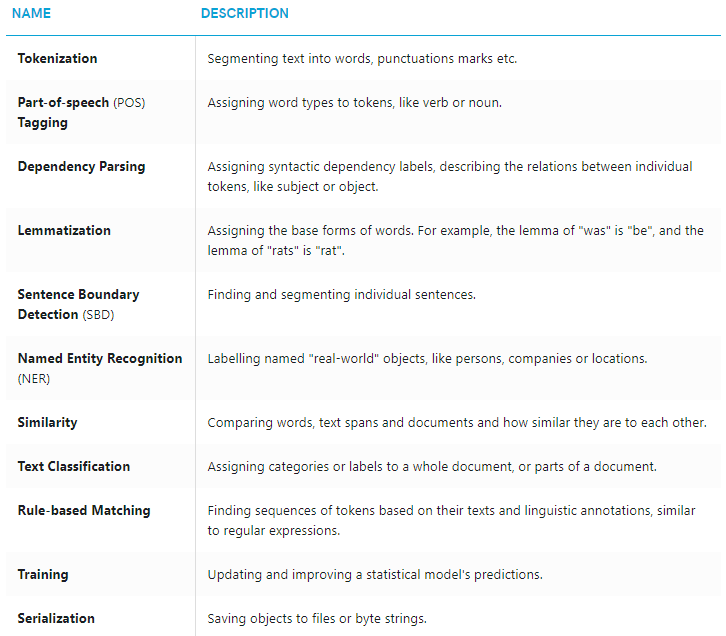
仅spaCy的分词(tokenization)就支持31种语言和嵌套分词:
6. pytext — 深度学习+ NLP + PyTorch
来自facebook的开源项目pytext是基于pytorch的,自身带着一股研究性(如果你想寻找深度学习+ NLP 的论文实现),如David 9 在之前文章(一维卷积在语义理解中的应用,莫斯科物理技术学院开源聊天机器人DeepPavlov解析及代码)提到的一维卷积:
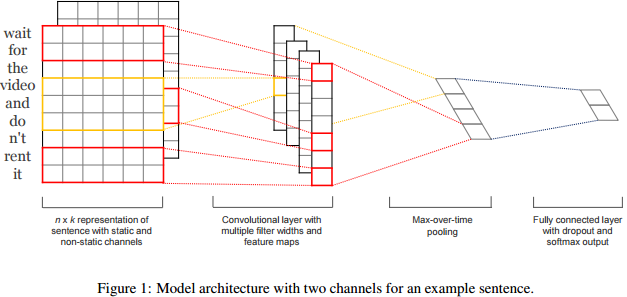
来自:https://arxiv.org/pdf/1408.5882.pdf
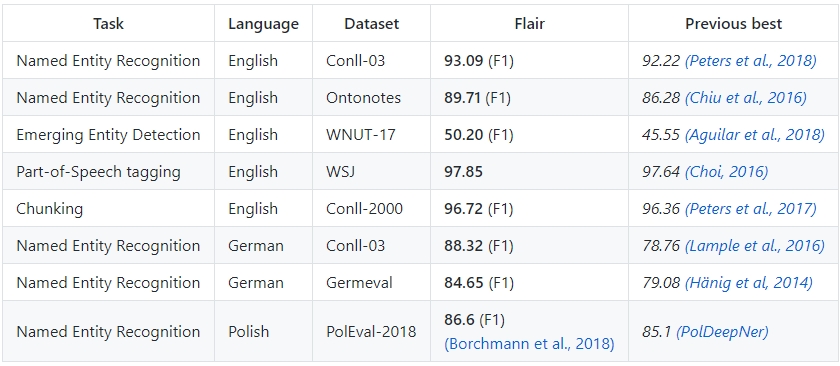
除了简单易用,与pytext不同的是,flair不专注于神经网络,但也对近年来一些成熟的方案给出了实现:
flair另一个亮点是有自己一套简单的方式组合不同的词嵌入(
embeddings ) ,包括
Flair embeddings, BERT embeddings 和LMo embeddings。
参考文献:
- https://heartbeat.fritz.ai/top-7-libraries-and-packages-of-the-year-for-data-science-and-ai-python-r-6b7cca2bf000
- https://heartbeat.fritz.ai/automated-machine-learning-in-python-5d7ddcf6bb9e
- https://github.com/zalandoresearch/flair
- https://github.com/mdbloice/Augmentor
- https://github.com/facebookresearch/PyText
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024