“人工感知”还将继续,但是人的“灵性” 绝非梯度学习和一堆权重这么简单— David 9
David最近一直在思考,Geoff Hinton等人热衷的“人工感知”最后会以什么样的方式让人们失去兴趣?优化方法(梯度学习、反向传播)和硬件技术(量子计算、边缘计算)的革新都不会直接影响其发展。 但一种可能是,那些感知难以触及的“信息处理”过程。
如小时候的你能感知到一个大家伙的存在(但无法表达),这时妈妈告诉你这是“飞机”:

这时你的大脑做的绝不仅仅是感知了,也不仅仅在这个“大家伙”打上“飞机”标签,它要处理的信息甚至超过我们的想象:它要知道究竟什么是“飞机”?“飞机”为什么会动?等等。。它还要感受母爱,这些感知和非感知的交错信息处理问题,已经超出了目前深度感知模型的范畴。
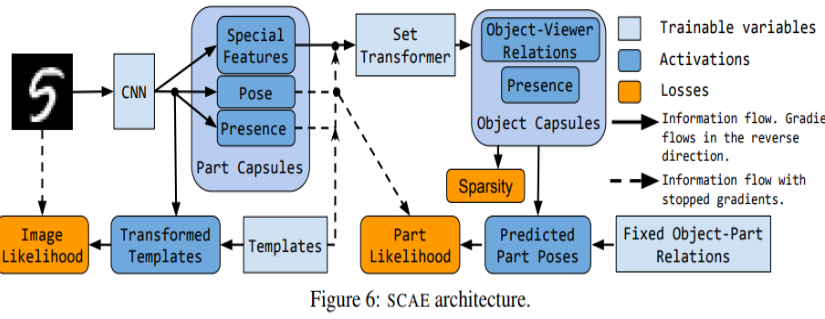
言归正转,Hinton在这次AAAI2020主题演讲上带来了最新的胶囊网络框架,并且否定了之前的所有的胶囊网络方法。他把这个框架叫:Stacked Capsule Autoencoders(堆叠胶囊自编码器)。
首先,他全面地阐述了为什么现在的CNN模型都是“垃圾”:
1. CNN只对不同视觉角度的物体是什么样有概念,一旦物体旋转一下(或拉伸一下等常规操作),CNN就傻眼了:

CNN太关注不变性(Invariance)信息了,而忽略了等价性(Equivariance)信息,一个物体,即使视觉角度变了,大小变了,或被拉伸了(不是钢体),它还是它!四个轮子的是汽车,两个轮子的是单车,橡皮泥被捏成任何形状,它还是橡皮泥:

2. CNN处理图像方法太怪异。CNN是根据“像素上下文”去判定一个物体的,即,确定一辆汽车,它的判断方法是,这个物体的2D纹理是不是和训练集中汽车的2D纹理相似,甚至这辆汽车是不是四个轮子也不重要:

 这就导致CNN和人类感知的方式差别太大,同样的图片加一些噪声可以作为攻击CNN的对抗样本:
这就导致CNN和人类感知的方式差别太大,同样的图片加一些噪声可以作为攻击CNN的对抗样本:
3. CNN没有人类直觉中的“巧合对比”概念。我们的眼睛试图寻找一个物体时,
