过去十年是云计算(集中式计算)流行的十年,我们不知道什么时候分布式或其他形式的“分散式计算”会“卷土重来”,但我似乎看到了“暗流涌动”。 — David 9
补充上一期我们聊到的“Tesla自动驾驶搞定多任务学习”,这次,特斯拉AI负责人Andrej Karpathy在PyTorch DEVCON 2019上进一步讨论了内部整体架构:

其中主要谈了两点:“PyTorch distributed training” 和 infrastructure 层面的一些东西。
继续上次的讨论,我们知道特斯拉autopilot自动驾驶不借助LIDAR激光而是通过八个方向的摄像头进行环境判断:

最后对模型来说要有一个top-down的俯视图做最终决策:

这就要求autopilot模型不断接受从8个摄像头捕捉到的图像,并同时输出许多output(1000个左右),而且,模型同时承载多个任务(目标检测,深度检测,目标识别等等),整个autopilot模型会包含许多个子模型(子任务):
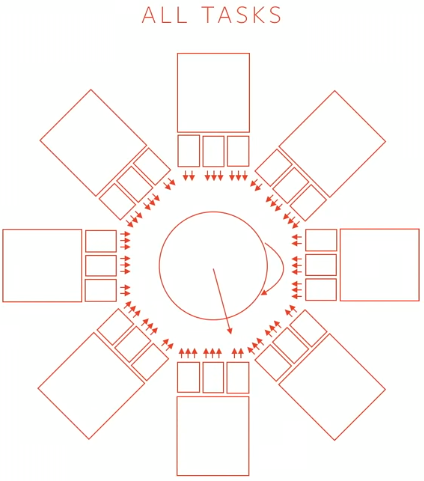
事实上,上图的8个子模型其实是简化了,其实auopilot有48个子模型。上图只是象征性地展示多模型同时有很多输出。而反向传播更新时, 继续阅读Tesla自动驾驶Autopilot(第2弹):多任务分布式PyTorch训练,FSD芯片,NPU,Dojo和其他