
你曾经有没有根据声音预测人的面容?或者,看一个陌生人一面,你在心里其实已经预测了他说话的声音?
今年CVPR2019上的Speech2Face模型就试图还原这一过程。虽然David认为模型上没有什么新意,但是这篇文章的一些实验结论很有意思。
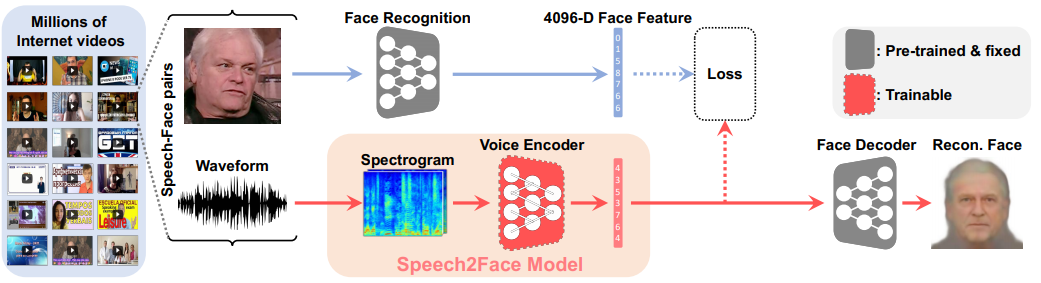
模型上中规中矩,先预训练Face encoder和decoder(灰色块部分),让模型可以压缩脸部特征并根据脸部特征向量还原出图像。然后,引入Voice Encoder,把音频一样压缩到特征向量(红色块部分),这个音频特征向量应该可以用来很好地预测对应的人脸,如果预测不好,就应该增加Loss,反向反馈训练。
了解原理之后,最有意思的其实是一些统计实验结论, 继续阅读MIT实验室Speech2Face模型: 听声音想象人脸,David9的CVPR2019观察