
如果你想成为大师,是先理解大师做法的底层思路,再自己根据这些底层思路采取行动? 还是先模仿大师行为,再慢慢推敲大师的底层思路?或许本质上,两种方法是一样的。 — David 9
聊到强人工智能,许多人无疑会提到RL (增强学习) 。事实上,RL和MDP(马尔科夫决策过程) 都可以归为策略学习算法的范畴,而策略学习的大家庭远远不只有RL和MDP:
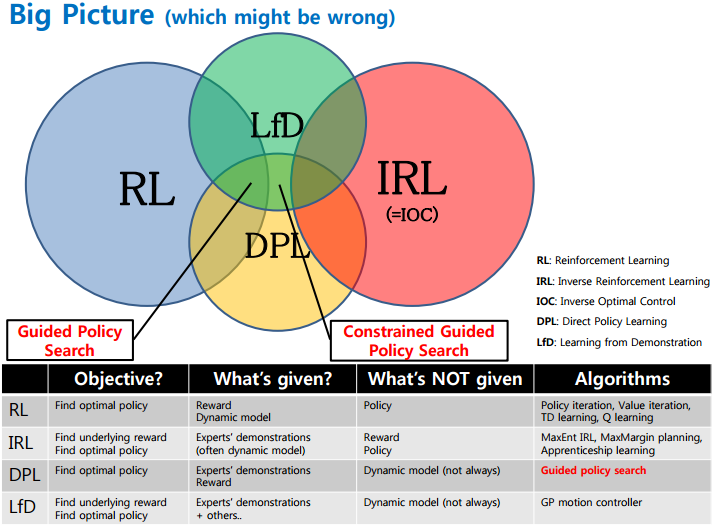
我们熟知的RL是给出行为reward(回报)的,最常见的两种RL如下:
1. 可以先假设一个价值函数(value function)然后不断通过reward来学习更新使得这个价值函数收敛。价值迭代value iteration算法和策略policy iteration算法就是其中两个算法(参考:what-is-the-difference-between-value-iteration-and-policy-iteration)。之前David 9也提到过价值迭代:NIPS 2016论文精选#1—Value Iteration Networks 价值迭代网络) 继续阅读GAN+增强学习, 从IRL和模仿学习, 聊到TRPO算法和GAIL框架, David 9来自读者的探讨,策略学习算法填坑与挖坑