
命名实体识别 (NER) 是语义理解中的一个重要课题。NER就像自然语言领域的“目标检测”。找到文档D 中的名词实体还不够,许多情况下,我们需要了解这个名词是表示地点(location),人名(Person)还是组织(Organization),等等:

上图是NER输出一个句子后标记名词的示例。
在神经网络出现之前,几乎所有NER半监督或者非监督的方法,都要依靠手工的单词特征或者外部的监督库(如gazetteer)达到最好的识别效果。
手工的单词特征可以方便提炼出类似前缀,后缀,词根,如:
-ance, —ancy 表示:行为,性质,状态/ distance距离,currency流通
-ant,ent 表示:人,…的/ assistant助手,excellent优秀的
–ary 表示:地点,人,事物/ library图书馆,military军事
可以知道-ant结尾的单词很可能是指人,而-ary结尾更可能指的地点。
而外部的监督库(如gazetteer),把一些同种类的实体聚合在一起做成一个库,可以帮助识别同一个意思的实体,如:
auntie其实和aunt一个意思:姨妈
Mikey其实是Mike的昵称,都是人名
今天所讲的这篇卡内基梅隆大学的论文,用RNN神经网络的相关技术避开使用这些人工特征,并能达到与之相当的准确率。
为了获取上述的前缀,后缀,词根等相关特征,文章对每个单词的每个字母训练一个双向LSTM,把双向LSTM的输出作为单词的特殊embedding,和预训练eStack LSTM的算法识别命名实体,感兴趣可以继续阅读原论文。mbedding合成最后的词嵌入(final embedding):
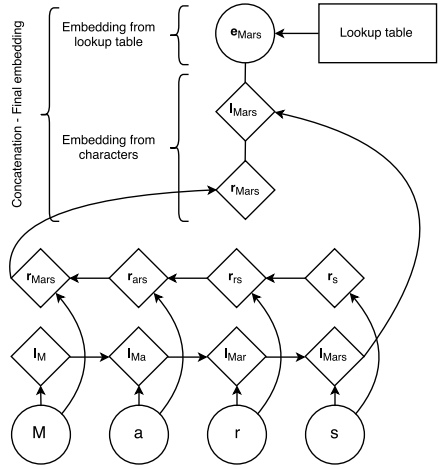
双向LSTM可以捕捉字母拼写的一些规律(前缀,后缀,词根), 预训练的embedding可以捕捉全局上单词间的相似度。两者结合我们得到了更好的词嵌入(embedding)。 继续阅读当RNN神经网络遇上NER(命名实体识别):双向LSTM,条件随机场(CRF),层叠Stack LSTM, 字母嵌入