有太多小伙伴问David 9关于Tensorboard的入门了,
我们都知道tensorflow训练一般分两步走:第一步构建流图graph,第二步让流图真正“流”起来(即进行流图训练)。
tensorboard会对这两步都进行跟踪,启动这种跟踪你必须先初始化一个tensorflow的log文件writer对象:
writer = tf.train.SummaryWriter(logs_path, graph=tf.get_default_graph())
然后启动tensorboard服务:
[root@c031 mnist]# tensorboard --logdir=/tmp/mnist/2 TensorBoard 1.5.1 at http://c031:6006 (Press CTRL+C to quit)
即可看到你定义的流图:
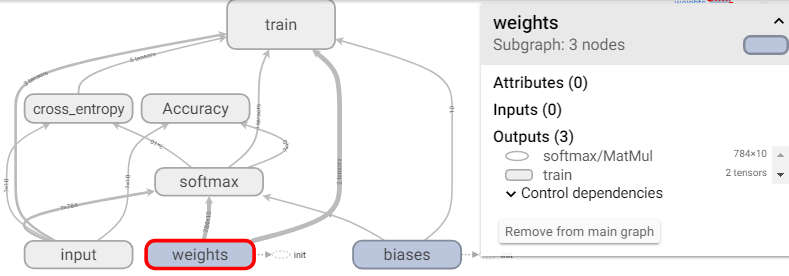
GRAPHS中的每个方框代表tensorflow代码中的scope作用域,比如上图就定义了7个作用域:train, cross_entropy, Accuracy, softmax, input, weights, biases. 每个作用域下都可能有一些Variable或者计算操作的Tensor,可以对方框双击鼠标放大:
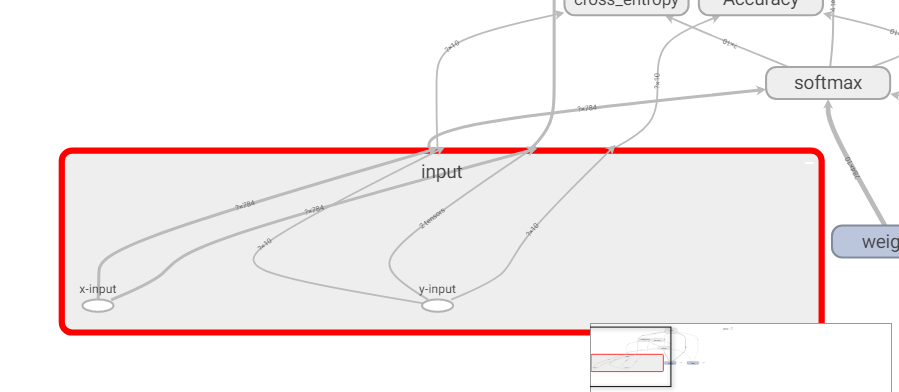 上图可见,input的scope下有两个placeholder:x-input和y-input. 继续阅读tensorboard快速上手,tensorboard可视化普及贴(代码基于tensorflow1.2以上)
上图可见,input的scope下有两个placeholder:x-input和y-input. 继续阅读tensorboard快速上手,tensorboard可视化普及贴(代码基于tensorflow1.2以上)