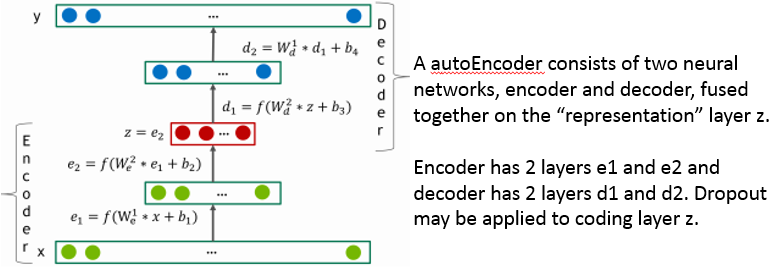
有时候,读读工程类的文章,虽然简单,但是能看到别人踩过的坑用过的tricks,也是挺有意思。NVIDIA不久前放出的协同过滤新标杆DeepRecommender 以Netfix 2009年的netflixprize竞赛数据为基准,使用基于自编码器的协同过滤,准确率比普通模型都高。
netflixprize竞赛目标非常简单,预测一个用户对一部影片评分的可能值(Netflix要推荐用户最感兴趣的影片来赚钱,不是吗?)事实上,评价竞赛分数的loss函数也很简单,是一个均方误差: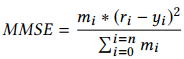 ri是真实评分,yi是模型预测评分,mi是一个外加的mask控制项,如果真实评分ri=0,那mi=0,否则mi就可以等于1. 继续阅读DeepRecommender:基于自编码器的协同过滤(Collaborative Filtering),英伟达论文选读及其pytorch实现
ri是真实评分,yi是模型预测评分,mi是一个外加的mask控制项,如果真实评分ri=0,那mi=0,否则mi就可以等于1. 继续阅读DeepRecommender:基于自编码器的协同过滤(Collaborative Filtering),英伟达论文选读及其pytorch实现