
无论是机器学习还是人类学习,似乎一个永恒的问题摆在外部指导者的面前:“我究竟做错了什么使得它(他)的学习效果不理想?” — David 9
之前我们提到过,端到端学习是未来机器学习的重要趋势。
可以想象在不久的将来,一切机器学习模型可以精妙到酷似一个“黑盒”,大多数情况下,用户不再需要辛苦地调整超参数,选择损失函数,尝试各种模型架构,而是像老师指导学生一样,越来越关注这样一个问题:我究竟做错了什么使得它的学习效果不理想?是我的训练数据哪里给的不对?
今年来自斯坦福的ICML最佳论文正是围绕这一主题,用影响函数(influence functions)来理解机器模型这一“黑盒”的行为,洞察每个训练样本对模型预测结果的影响。
文章开篇结合影响函数给出单个训练样本 z 对所有模型参数 θ 的影响程度 I 的计算:
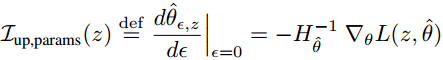
其中 ε 是样本 z 相对于其他训练样本的权重, 如果有 n 个样本就可以理解为 1/n 。
![]()
是Hessian二阶偏导矩阵, 蕴含所有训练样本(总共 n 个)对模型参数θ 的影响情况.
而梯度![]()
蕴含单个训练样本 z 对模型参数 θ 的影响大小. 继续阅读ICML 2017论文精选#1 用影响函数(Influence Functions)理解机器学习中的黑盒预测(Best paper award 最佳论文奖@斯坦福)