第五届ICLR(ICLR2017)最近被炒的厉害,David 9回顾去年著名论文All you need is a good init,当时提出了一种新型初始化权重的方法,号称在Cifar-10上达到94.16%的精度,碰巧最近在看Keras。
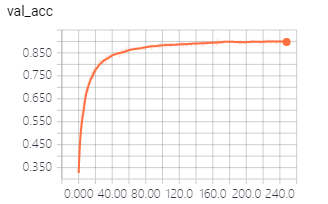
好!那就用Keras来还原一下这个Trick。效果果然不错,没怎么调参,差不多200个epoch,testing准确率就徘徊在90%了,training准确率到了94%:
第五届ICLR(ICLR2017)最近被炒的厉害,David 9回顾去年著名论文All you need is a good init,当时提出了一种新型初始化权重的方法,号称在Cifar-10上达到94.16%的精度,碰巧最近在看Keras。
好!那就用Keras来还原一下这个Trick。效果果然不错,没怎么调参,差不多200个epoch,testing准确率就徘徊在90%了,training准确率到了94%:
抽样方法的改进似乎像人类进化一样永无休止 — David 9
CVPR 2017机器视觉顶会今年6月21号才举办,但是2016年11月就投稿截止了。微软每年都是CVPR大户,今天我们要讲解的就是MSRA微软亚洲研究院的最新投稿论文:Deformable Convolutional Networks。(很可能被收录哦~)我们暂且翻译为:可变形卷积网络。
这是一种对传统方块卷积的改进核。本质是一种抽样改进。
谈到抽样,人脑好像天生知道如何抽样获得有用特征,而现代机器学习就像婴儿一样蹒跚学步。我们学会用cnn自动提取有用特征,却不知用什么样的卷积才是最有效的。我们习惯于方块卷积核窗口,而Jifeng Dai的work认为方块不是最好的形状:
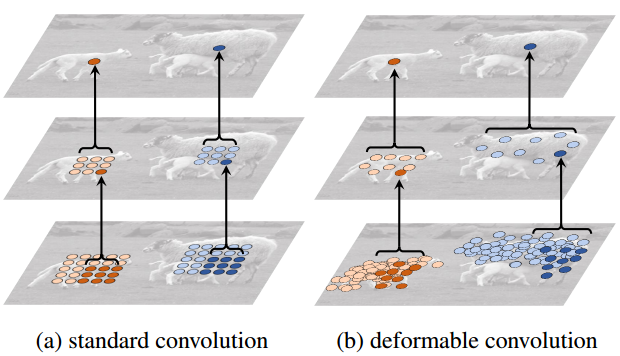
如果能让网络自己学习卷积窗口形状,是不是一件很美好的事情? 继续阅读MSRA微软亚洲研究院 最新卷积网络: Deformable Convolutional Networks(可变形卷积网络)
人类擅长把一个问题转化为另一个问题,而深度学习试图把所有问题转化为同一个问题 — David 9
现代深度学习或机器学习,很大程度上是把所有问题转化为同一个“模型训练”问题。如何解决这个模型训练的问题成为了数据科学家们的主攻问题。
鲜为人知的是,设计机器学习模型、训练算法和目标函数仅仅是工作的一部分。还有很重要的一部分是:数据科学家们要对数据和问题有更深层次的理解,对于模型评估, 超参数调优,网格搜索,调试策略都有相当的实践经验。
正如Deep Learning(Ian Goodfellow Yoshua Bengio)一书中所说:
Correct application of an algorithm depends on mastering some fairly simple methodology