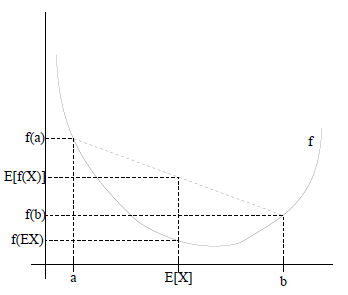
今天David 9要带大家读偶像Hinton等大牛的一篇论文,搞深度学习或者DL的朋友应该知道,那就是有名的Dropout方法。
学过神经网络的童鞋应该知道神经网络很容易过拟合。而且,如果要用集成学习的思想去训练非常多个神经网络,集成起来抵制过拟合,这样开销非常大并且也不一定有效。于是,这群大神提出了Dropout方法:在神经网络训练时,随机把一些神经单元去除,“瘦身”后的神经网络继续训练,最后的模型,是保留所有神经单元,但是神经的连接权重 乘上了一个刚才随机去除指数
乘上了一个刚才随机去除指数 .
.
废话少说,上原理图:
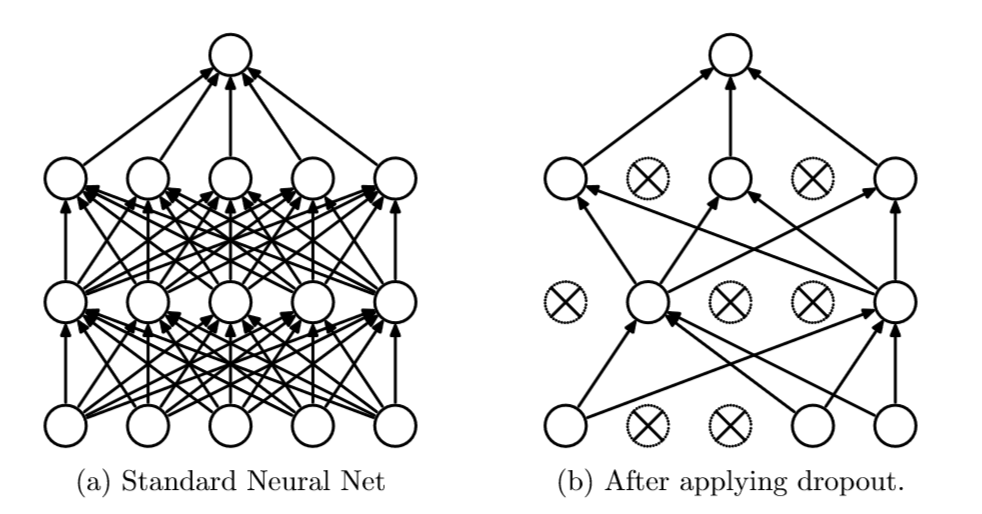
左边是标准神经网络,右边是使用Dropout的神经网络,可见只是连接度少了一些,并不影响模型继续训练。其实,Dropout动机和初衷非常有意思。 继续阅读神经网络抵制过拟合神器:Dropout 手把手论文入门 — 深度学习 DL 番外篇
 是定义域为实数的函数,如果对于所有的实数
是定义域为实数的函数,如果对于所有的实数 ,
, ,那么
,那么 ),那么
),那么 或者
或者 , 那么称
, 那么称
 当且仅当,也就是说
当且仅当,也就是说 是常量。
是常量。