1. Pip
如果已经安装过pip,可以跳过这里的安装步骤。
$ sudo apt-get install python-pip python-dev python-setuptools build-essential
$ sudo pip install --upgrade pip
$ sudo pip install --upgrade virtualenv
为了检测是否安装好,可以查看pip的版本:
$ pip --version
pip 8.1.2 from /usr/local/lib/python2.7/dist-packages (python 2.7)
2. Tensorflow
接下来,就可以按照Tensorflow Download and Setup中的Pip Installation开始安装,命令如下:
# Ubuntu/Linux 64-bit, CPU only:
$ sudo pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.8.0-cp27-none-linux_x86_64.whl
继续阅读[转] Ubuntu14.04LTS安装TensorFlow
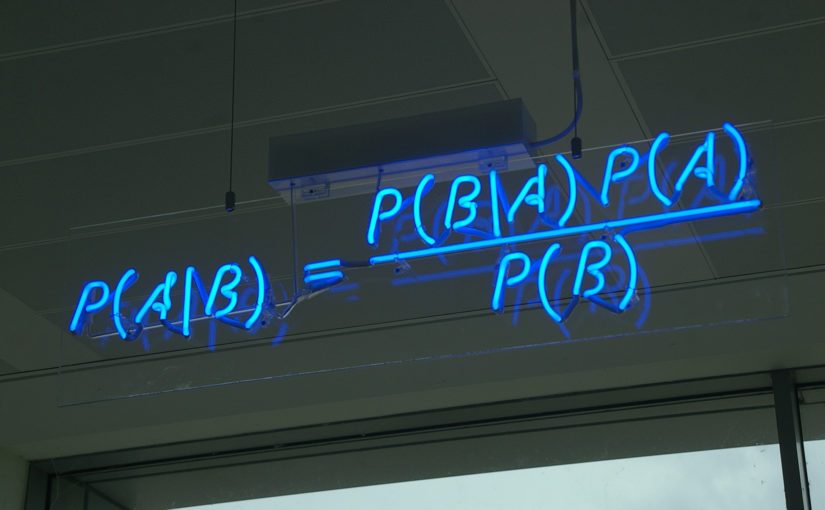

 代表一个模型,
代表一个模型,  , 如果
, 如果  , 那么这个模型就是最好的. 当然这是不可能的, 也许只有上帝才能对所有的未知100%准确预测. 但我们一定是希望
, 那么这个模型就是最好的. 当然这是不可能的, 也许只有上帝才能对所有的未知100%准确预测. 但我们一定是希望  越大越好, 趋向于1.
越大越好, 趋向于1.
 是真实的训练数据或者抽样数据 .
是真实的训练数据或者抽样数据 .  是后验概率(posterior)分布 .
是后验概率(posterior)分布 .  是似然概率(likelihood).
是似然概率(likelihood).  是先验概率分布(prior).
是先验概率分布(prior).  是归一化”证据”(evidence)因子.
是归一化”证据”(evidence)因子.

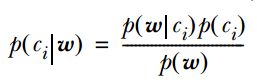
 的计算方法, 而由朴素贝叶斯的前提假设可知:
的计算方法, 而由朴素贝叶斯的前提假设可知: 
{kind=link}