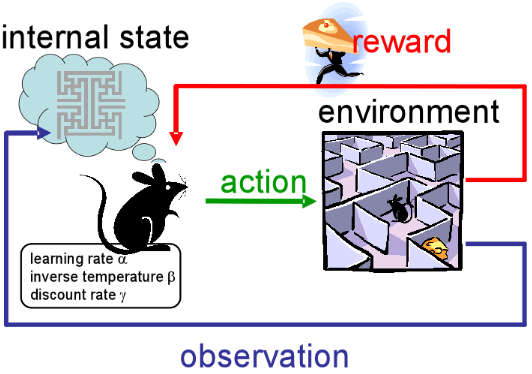
是先用自己的”套路”边试边学, 还是把所有情况都考虑之后再总结, 这是一个问题 — David 9
David 9 本人并不提倡用外部视角或者”黑箱”来看待”智能”和”机器学习”.
正如《西部世界》迷宫的中心是自己的内心. 神经网络发展到目前的深度学习, 正是因为内部的结构发生了变化(自编码器, 受限玻尔兹曼机, 改进的激活函数, 等等…) . 所以David 9 相信神经网络未来的发展在于人类对内部结构的新认知, 一定有更美的内部结构存在 !
而今天所说的增强学习, 未来更可能作为辅助外围框架, 而不是”智能核心”存在. 不过作为闪电入门, 我们有必要学习这一流行理论:
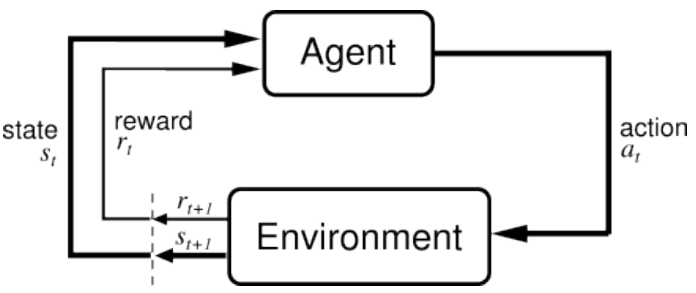
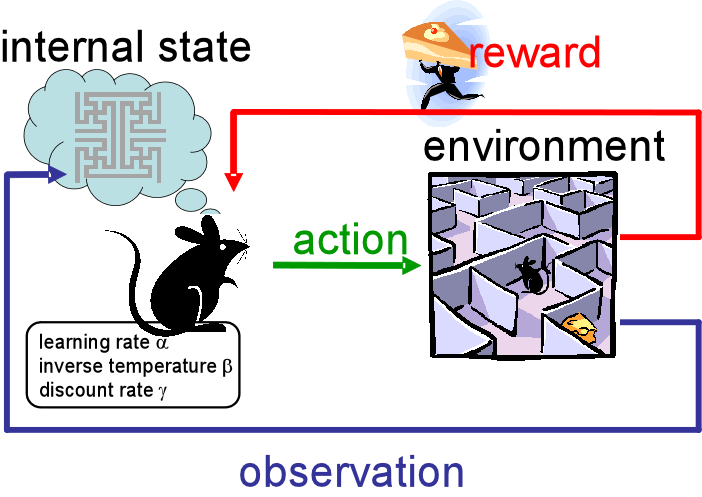
没错, 这张图和文章特色图片是一个思想:
训练实体(Agent)不断地采取行动(action), 之后转到下一个状态(State), 并且获得一个回报(reward), 从而进一步更新训练实体Agent.
就像要训练小老鼠走出迷宫, 你可以在迷宫的几个关键地点放上奶酪, 这些奶酪就是算法中的回报(reward)了, 剩下你只要坐着等小老鼠走出迷宫啦:
当然这个简单思想的背后是马尔可夫决策过程(MDP):
一个马尔可夫决策过程由一个四元组构成M = (S, A, Tsa, R)
- S: 表示状态集(states),有s∈S,si表示第i步的状态。
- A:表示一组动作(actions),有a∈A,ai表示第i步的动作。
- Tsa: 表示状态转移概率。s 表示的是在当前s ∈ S状态下,经过a ∈ A作用后,会转移到的其他状态的概率分布情况。比如,在状态s下执行动作a,转移到s’的概率可以表示为p(s’|s,a)。
- R: S×A⟼ℝ ,R是回报函数(reward function)。有些回报函数状态S的函数,可以简化为R: S⟼ℝ。如果一组(s,a)转移到了下个状态s’,那么回报函数可记为r(s’|s, a)。如果(s,a)对应的下个状态s’是唯一的,那么回报函数也可以记为r(s,a)。
MDP 的动态过程如下:某个智能体(agent)的初始状态为s0,然后从 A 中挑选一个动作a0执行,执行后,agent 按Psa概率随机转移到了下一个s1状态,s1∈ Ts0a0。然后再执行一个动作a1,就转移到了s2,接下来再执行a2…,我们可以用下面的图表示状态转移的过程。
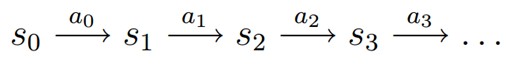
我们知道, 增强学习的本质是学习从环境状态到动作的映射(即行为策略),记为策略π: S→A。而仅仅使用立即回报r(s,a)肯定是不够的(一个策略π的长期影响才是至关重要的).
因此, 衍生出了两个增强学习的训练算法: 价值迭代和策略迭代
考虑下面这个简单的迷宫问题:

从入口(Start)走到出口(Goal)就算胜利. 小方格的位置就是我们状态S, 行为Action只有四种(上下左右), 回报函数就定为每远离一步Goal, 回报-1.
价值迭代
如果使用价值迭代算法, 我们更新每个状态s的长期价值V(s), 这个价值是立即回报r(s,a)与下一个状态s+1的长期价值的综合(想想是不是很有道理?), 从而获得更新:
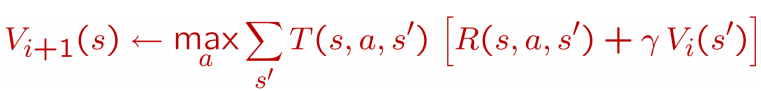
有两个点要注意:
- 每次迭代, 对于每个状态s, 都要更新价值函数V(s)
- 对于每个状态s的价值更新, 需要考虑所有行动Action的可能性, 这就非常消耗时间.
最后可以训练出所有状态s的价值, 大概是下面这样:

值得注意的是, 如果价值迭代完成后, 每个状态下一步的策略也就有了(选下一步价值较高的格子走, 就可以了)
策略迭代
如果使用收敛较快的策略迭代算法, 每次迭代我们分两步走:
第一步: 先任意假设一个策略πk , 使用这个策略迭代价值函数直到收敛,
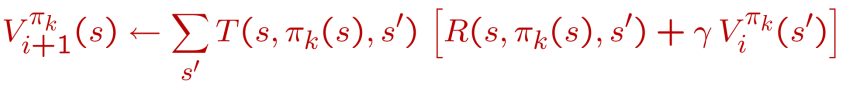
最后得到的V(s)就是我们用策略πk , 能够取得的最好价值函数V(s)了(其实是策略的一种评估)
第二步: 我们重新审视每个状态所有可能的行动Action, 优化策略πk, 看看有没有更好的Action可以替代老的Action:
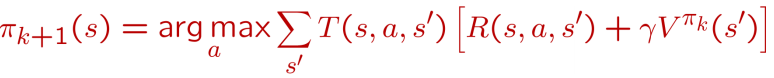
这样就最终优化了策略函数πk. 最终效果大概是这样的:
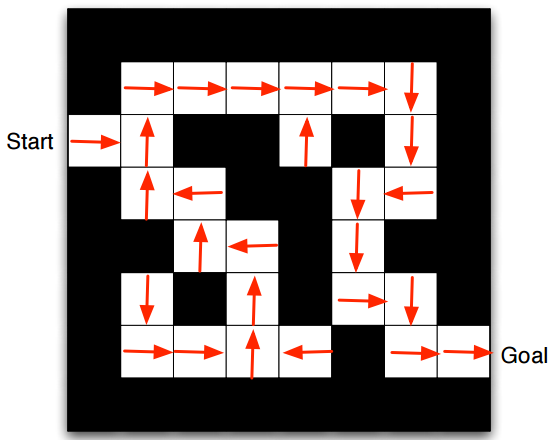
这就是策略迭代, 最后得到了每个状态应有的最佳策略.
正如我们开头说的, “是先用自己的”套路”边试边学, 还是把所有情况都考虑之后再总结”, 正是策略迭代与价值迭代的区别, 我们需要权衡考虑.
最后, 我们学习两组增强学习中的常用概念:
“模型学习”和”无模型学习”
这组思想其实在机器学习中都非常常见, 如果要解决一个问题, 我们一般有两种选择:
- 先假设一个模型, 然后通过一些手段, 后续优化和改进这个模型的参数, 最后达到最优
- 不使用模型, 直接用已有样本估计问题的期望.
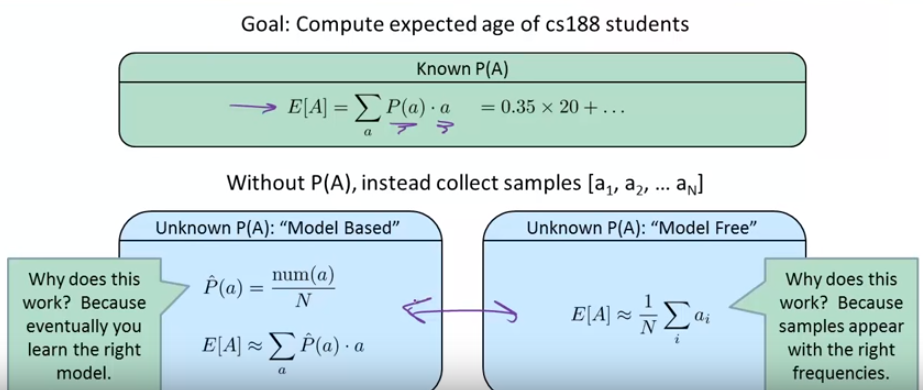
如上图的计算学生年龄期望的例子, 也是有两种方法对应“模型学习”和”无模型学习”:
- 先假设每个年龄有一个概率, 通过抽样去估计每个年龄的概率, 最后对于每个年龄求联合概率, 就是最终的年龄期望.
- 把所有抽样的年龄求和, 除以样本个数, 就是期望了.
“积极学习”和”消极学习”
消极学习是不采取任何行动Action改进策略的学习:
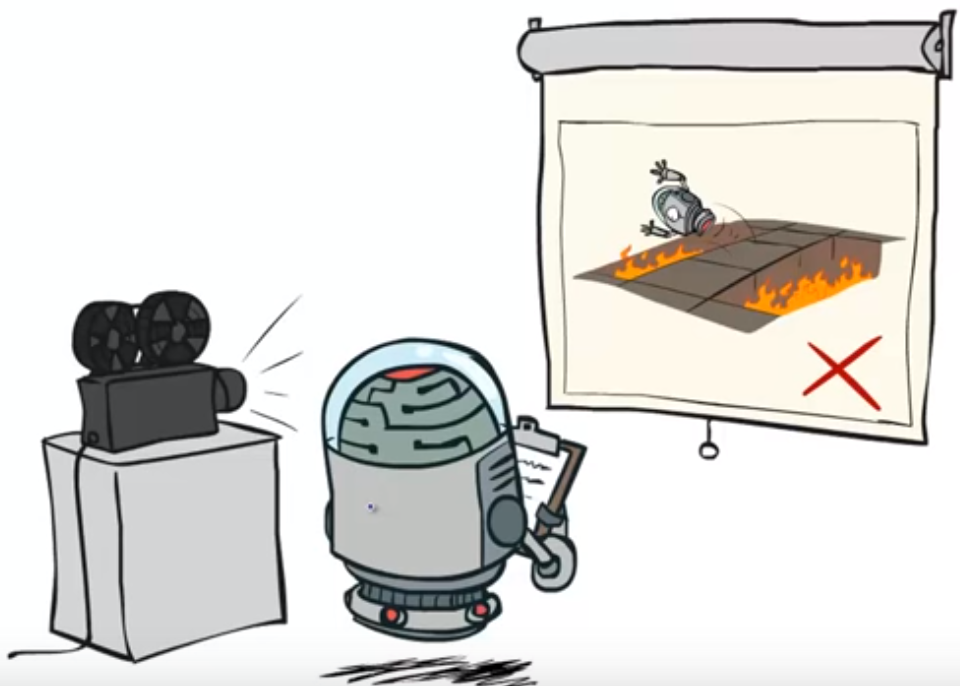
小机器人只是在视频中观看一些可能发生的情况和行为, 用来评估策略, 自己并没有采取行动改进策略.
这种只是”记录型”的学习, 有点像我们策略迭代的第一步, 策略评估. 没有考虑视频意外行为的可能性. 而”积极学习”则相反.
如果大家有意继续深入学习, 别忘了戳下面的参考文献. 以及, 要关注我的微信, 在下面二维码~
参考文献:
- https://www.youtube.com/watch?v=w33Lplx49_A
- https://www.youtube.com/watch?v=jUoZg513cdE
- https://www.youtube.com/watch?v=2pWv7GOvuf0&t=5s
- http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
- http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching_files/intro_RL.pdf
- http://www.cis.upenn.edu/~cis519/fall2015/lectures/14_ReinforcementLearning.pdf
- https://github.com/dennybritz/reinforcement-learning
- http://people.eecs.berkeley.edu/~russell/classes/cs188/f14/lecture_videos.html
- 增强学习(二)—– 马尔可夫决策过程MDP
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024