
AI的进步是不断为机器赋能: “深蓝”时代机器有了暴力搜索能力, “数据”时代有了依靠数据建模的能力, 甚至用GAN自动寻找目标函数. 下一个时代, 会不会是一个数据和模型泛滥, 机器自我寻找数据和创造模型的时代 ? — David 9
之前伯克利人工智能研究实验室(Berkeley Artificial Intelligence Research (BAIR) Lab)在Arxiv上放出的论文: Image-to-Image Translation with Conditional Adversarial Networks , 又把图片风格转换玩了一把:

如今, 想把GAN(生成对抗网络)训练出来并且不玩坏, 已经很了不起, 而这篇文章提出通用的框架用于”图片到图片”的风格转换. 加之投稿即将举办的cvpr 2017 , 又出自伯克利之手, 引来了不少目光.
用条件对抗网络cGAN进行图片风格转换已经不是新鲜事, 但是之前的研究总是局限于单个领域, 而本论文提出的方法是一种通用的训练方式, GAN可自动训练需要转换的样式风格, 而不仅限于一个应用范畴, 如下图:
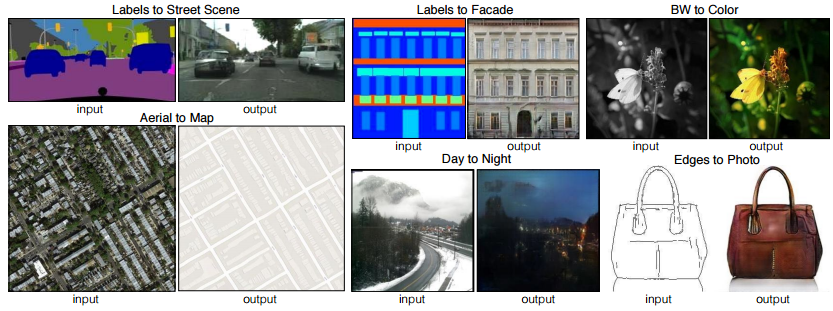
无论是从“抽象到复杂”还是从“复杂到抽象”, 无论是卫星图还是商品或是植物,都可进行自适应风格转换。其灵活性得益于cGAN网络结构独特的设计, 伯克利对cGAN的生成器和判别器都做了非传统的修改. (如果你还不知道什么是生成器和判别器, 有必要看一下我们之前的文章)
首先我们看下这篇文章cGAN全貌:
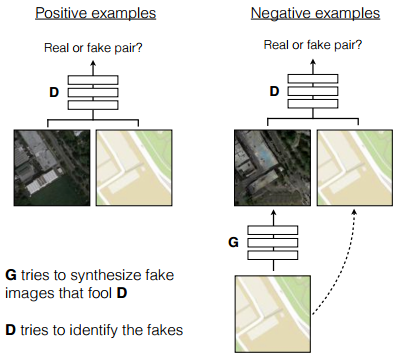
如上图,与传统GAN不同的是, cGAN的输入是成对出现的两张图片。判别器所要做的是判别两张图片的第二张图片是否是适当样式处理过的图片,即,判断两张成对图片是否是真实的样式转换。生成器所要做的是根据原始图片(第一张图片)生成欺骗判别器的尽量真实的转换图片。
因此,cGAN在输入上多了一个输入的条件图片x:
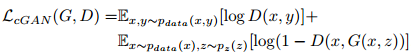
损失函数里的(x, y)就是一个图片对,x是条件图片,y是真实风格转换后的图片。而图片对(x,z)中z 是生成模型生成的风格转换后图片。
实际中使用L1正则能够比L2正则生成更清晰的图片,所以论文中使用L1正则:
![]()
所以最终目标函数如下:
![]()
除了目标函数,更显著的不同是生成器采用了独特的U-net网络:
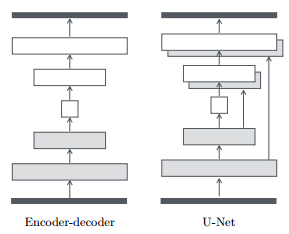
其中U-net架构把Encoder与Decoder的各个对称层直接相连(层的输出直接拼接到对称层的输入),因为, 在图片转换问题中, 待转换图片和转换后图片虽然风格不同, 但内在结构存在一些直接紧密的联系. 这些跳跃的层间连接使得图片转换时内在结构得到很好的反馈.
为了强调材质/风格的损失, 文章还使用了自己的判别器—PatchGAN. 这种判别器把每个卷积窗口中高频的结构记住, 计算损失的时候, 不关注这些高频结构, 尽量关注低频的patch像素范围, 这样就有了类似马尔科夫随机场的建模效果. 把材质/风格的损失放在首位.
并且文章指出PatchGAN这种判别器, 在卷积窗口比较小的情况下, 也有很好的效果:

如图, 70*70的卷积窗口是较好的效果. 如果过小, 就会产生不真实的人工像素效果; 如果过大, 又会显得像素不清晰.
参考文献:
- Image-to-Image Translation with Conditional Adversarial Networks
- https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
- https://github.com/phillipi/pix2pix
- https://github.com/affinelayer/pix2pix-tensorflow
- https://github.com/mrzhu-cool/pix2pix-pytorch
- http://cvpr2017.thecvf.com/
- https://www.computer.org/web/tcpami/cvpr-best-paper-award
- https://arxiv.org/pdf/1406.2661.pdf
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024