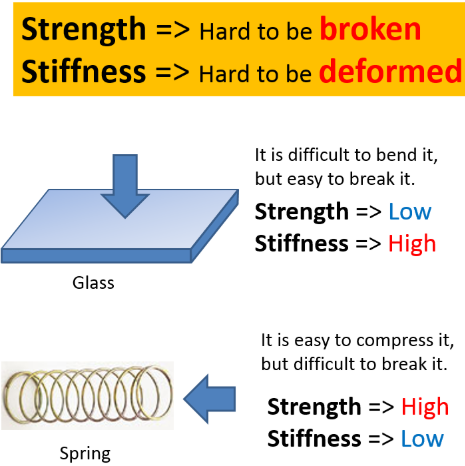
如果训练神经网络可以与人一样,其训练日程可以精心规划编排、且有不同的学习曲线和阶段、在不同的领域有不同“天赋”自主学习。总之,训练过程可以足够“复杂”,是否可以诱导出更好的模型? — David 9
假设神经网络有一个确切的决策边界,这个决策边界足够复杂可以帮我们分类10000+个类别,想象一下可能是这样复杂的:

但无论如何,归结到一个决策边界,是这样的:
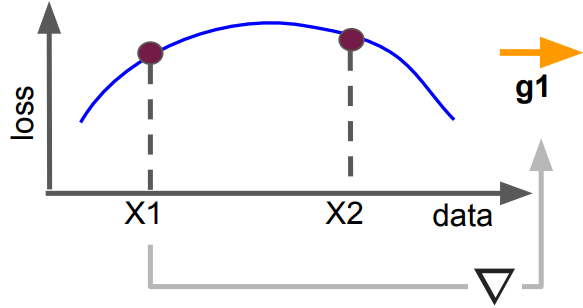
对于任意新的训练样本X1,如果要让X1的loss更小,需要用一个梯度g1更新网络,对决策边界的影响势必导致另一个新样本X2的loss可能变小、不变或变大:
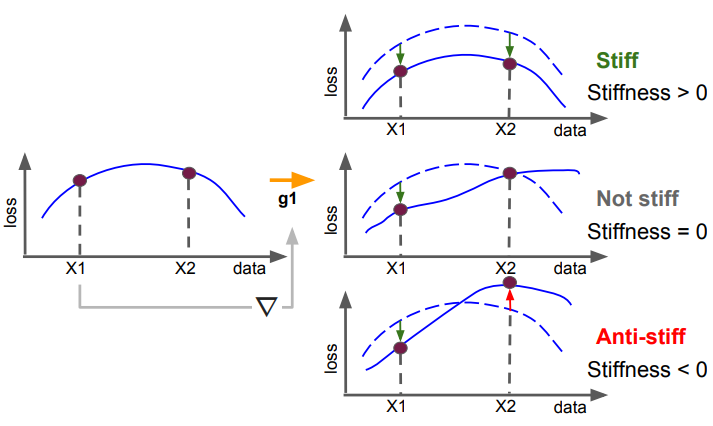
如果X2和X1一起变小,就认为神经网络的决策边界是“刚性”>0 (stiffness>0)的,以此类推,如果X2 loss不变,“刚性”=0(stiffness=0),如果 X2的loss反而变大了,“刚性”<0 (stiffness<0)。
一方面直观上,如果“刚性”处处大于0,这个网络的边界比较鲁棒,边界不容易“变形”;而如果神经网络“刚性”在许多情况小于0,决策边界就不得不在许多地方做类似“变形”的调整。
另外David认为“刚性”在一定程度上也体现了网络对新测试集的“自恰性”。论文中也指出“刚性”>0的情况其实就是两个样本需要更新的梯度g1和g2的一致性较大,而“刚性”<0则相反g1和g2梯度相背:
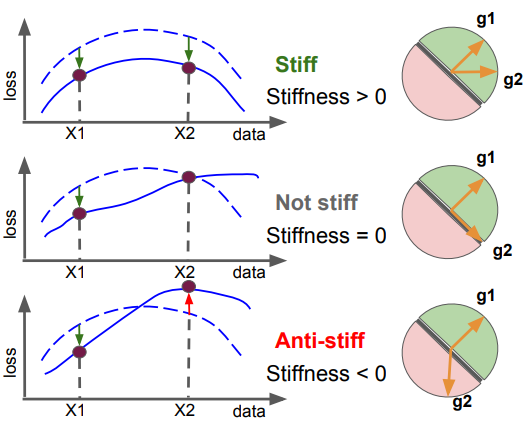
文章指出,当“刚性”<0即模型“自恰”性变得特别弱的时候(梯度更新非常混乱时),也往往是网络开始“过拟合”的时候:
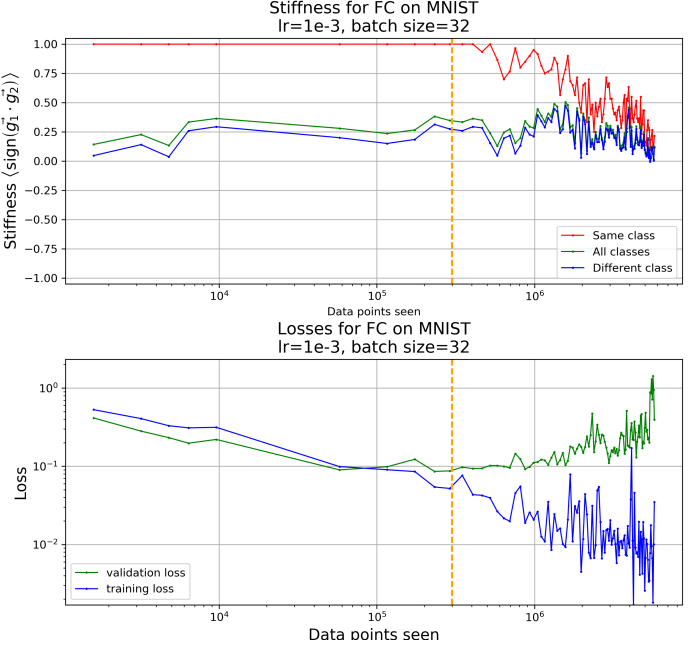
如上图,我们看到在垂直黄线处模型开始过拟合(平时是用下表loss来检测过拟合的),而观察到上表stiffness也是在黄线处开始减少的(特别是红色折线同类别样本之间的stiffness值)
另外还有一些有意思的现象:
对于MNIST集的0-9各个类别之间的“自恰性”(刚性),分别在迭代0次,800次,638176次,5627552次时的情况如下(横纵坐标分别代表两个类别):
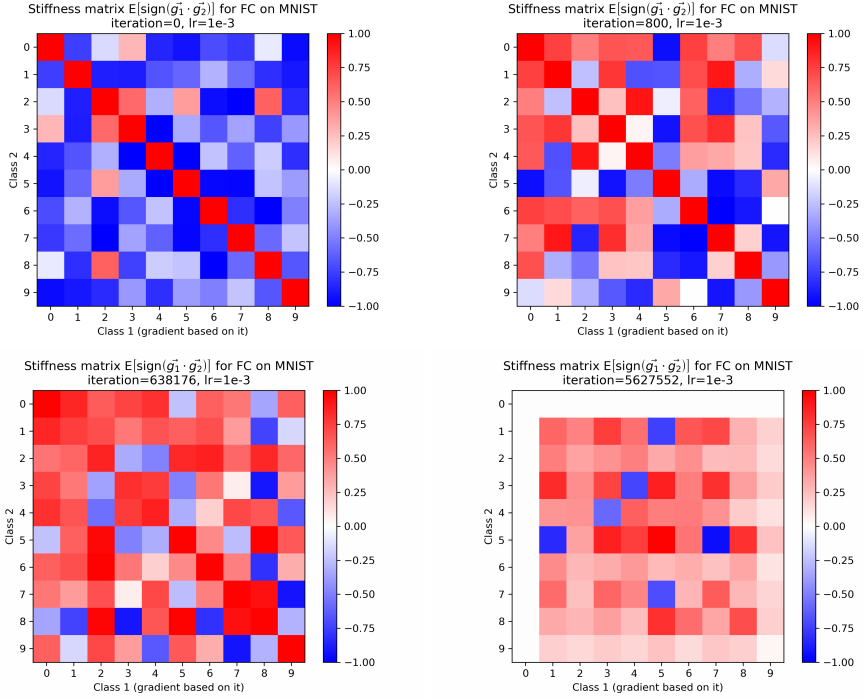
可见在训练初期,单个类别内样本间的“自恰性”(刚性)很大(注意对角线都是红色的高值),很有可能是模型初期决策边界比较宽泛,只是学习各个类别的大致信息,不关注各个类别具体差异(不在对角线上的类别间刚性极小)。
对于根本无法训练的随机数据集,模型“刚性”又是如何表现的呢:
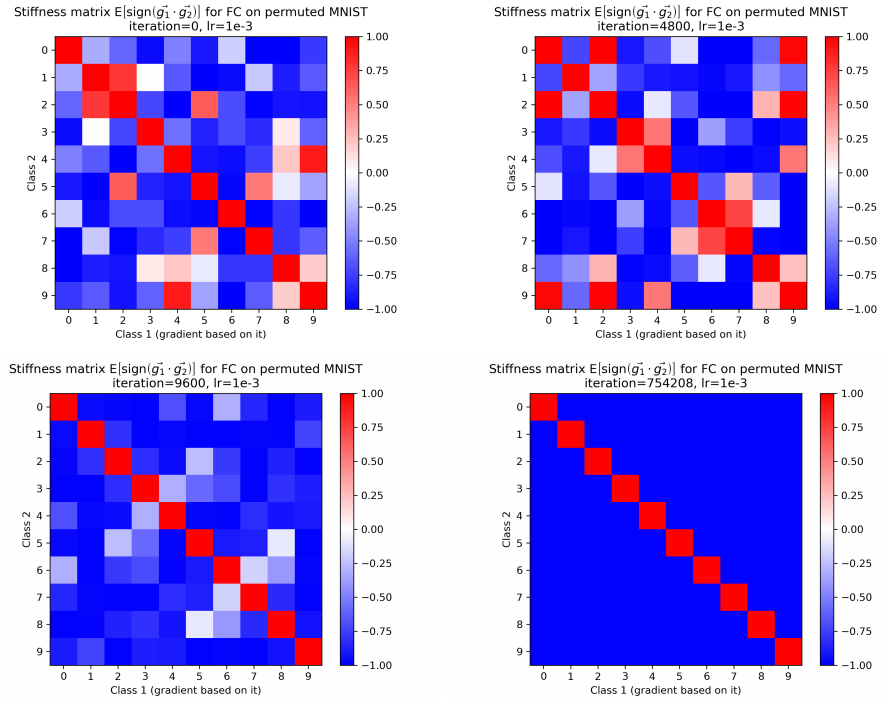
和直觉一样,网络无法从随机标签的样本中学到类别差异,因此类别之间的“刚性”多数都是非常低的值。
另外,文章也发现对于类别较多的cifar-100数据集,决策边界容易把小类别分更大的组,决策边界在同一个组内的“刚性”比较大:
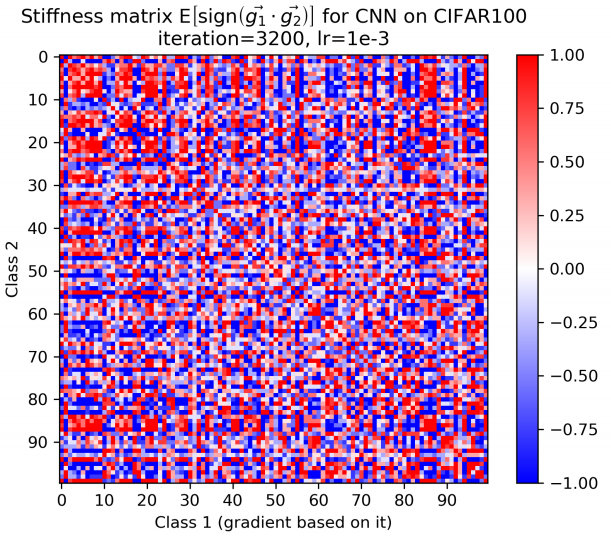
如上图注意到有红色的小块(大约5个类别一组),模型对于一些难以区分的类倾向于归为一组。在David看来,这是一个指导非平衡集训练的很好启发,如果让那些数据量非常少的类别的分组情况减少(“刚性”一致性减小),是不是可以改善这些少数类别总是分错的尴尬?
对于learning rate对网络“刚性”的影响,文章也做的讨论。实验表面,如果learning rate设的比较大,不同类别之间的“刚性”(自恰性)比较大:
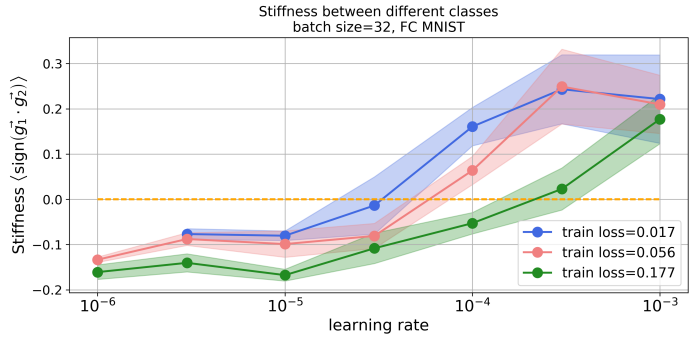
也就是说,如果你以后训练类别比较多的模型,可以考虑用较大的learning rate,去学习类别之间的信息。
最后,引发思考的是,训练样本用什么顺序输入到神经网络也有微妙的差别(样本对模型“刚性”影响是非常细粒度的)。
参考文献:
- Stiffness: A New Perspective on Generalization in Neural Networks
- https://www.intechopen.com/books/brain-computer-interface-systems-recent-progress-and-future-prospects/optimal-fractal-feature-and-neural-network-eeg-based-bci-applications
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024