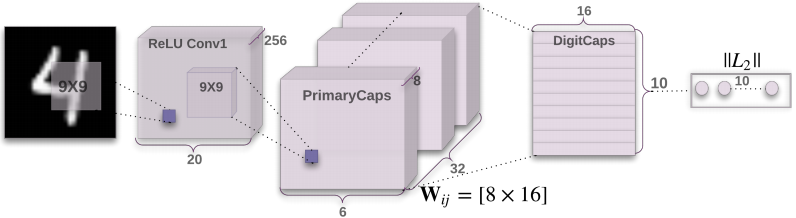
David 9 一直想扒一扒Hinton的胶囊网络,老教授两篇论文有些晦涩,但今天发现AI³普及帖不错,只是略显冗长。。所以,精华浓缩版就呼之欲出了O(∩_∩)O~
深度CNN是Hinton老教授10年前就在重点研究的课题,胶囊网络也是Hinton早已思考的内容,所以,
第一:胶囊网络不是空穴来风的新算法,而是基于CNN的缺陷和新需求的改进。
第二,胶囊网络比CNN好在哪里??
首先,CNN牛X之处在于用类似蛮力的海量数据方式,自动把重要的分类特征找到,所以,无论图像是不是完整,我们都有理由相信CNN能够识别图中有没有“米老鼠”这个对象:


只要CNN看到有象征米老鼠的“耳朵”和“鼻子”, CNN就认定这张图中有“米老鼠”。(哪怕拼图还没完成)
当然CNN缺陷是明显的,总结有下面两个问题:
1. 它很难有效识别图中位置的关系,下面两张图对CNN来说是同一个人的脸(哪怕人脸鼻子和眼睛是错位的):
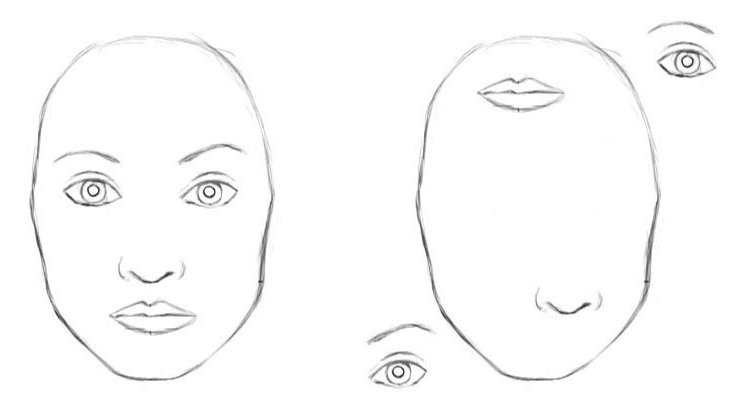
即,CNN蛮力的背后不能理解图片的语义(和位置关系)。
2. CNN没有空间分层和空间推理的能力。而人类的视觉系统可以轻松对下面的图片举一反三:

甚至在人脑中,只需要上图的1到2张图片,就可以推测出其他的图片都是“自由女神像”。而CNN需要

The following two tabs change content below.




David 9
邮箱:yanchao727@gmail.com
微信: david9ml
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
有两个小疑问想请教一下:
1、原文中说CNN“很难有效识别图中位置的关系”,不过我感觉CNN应该也会识别图中位置的关系吧?比如错位的那张图,实际对应到了不同neuron,CNN真的会当作同一张图片吗,不同max pooling 而用多个卷积层卷积的话,感觉似乎也会识别到位置关系?
2、原文说“CNN没有空间分层和空间推理的能力。而人类的视觉系统可以轻松对下面的图片举一反三”,我个人理解,人类的视觉系统能够轻松举一反三,同样是因为从小时候到长大从不同角度看了很多三维对应到二维的信息,学习了这个过程。当然,CNN确实缺乏快速获得空间推理的能力。我个人只是有点怀疑把人类多年学习得到的一些经验强加到网络上是不是有种揠苗助长,重新回归到早期规则抽取的方法的感觉哈哈。
博主的一系列文章对于我们新入门的新手帮助很大,不知道为啥没有多少留言~
如果实际只用卷积(没有pooling层)确实会对应不同的neuron,但是卷积操作你知道是连续的滑动(只关注局部连续区域),所以我觉得很难照顾到全局,所以那张错位图我觉得很可能全局上照顾不到(但是我也没实验过)。
哈哈第2个问题我觉得人类从小到大的训练确实是有帮助的。但是我认为,现阶段机器视觉把2D图就当做2D图训练很可能是一个错误,因为我们人类看一张照片,不自觉地就想到3D的场景,我们人脑的视觉空间应该是在3D维度的,这个点未来也许应该把握一下(也许是视觉语义的关键点)。
为啥没多少留言,哈哈,也许我的粉丝都比较懒吧,光顾着看文章了。。。
最近在GitHub上看见一个使用胶囊网络的程序,也查看了论文,但是没能理解胶囊网络的原理。现看博主博客,瞬间理解了CNN和胶囊网络。
各位都是高手啊,CV的发展路途还很遥远啊。
致敬高段位的学习者!
是的,David 9的文章都是高质量的学习经验。
如果你喜欢也请多转发到微信微博等,你的传播是对我们最大的支持!
您为什么说相对位置的解决方案是Pooling层,那个不是就压缩了信息吗?
pooling的压缩是一块一块有区域性(离散)的,所以包含了区域相对位置的信息。
如还有问题可以加我微信:david9ml