训练”稳定”,样本的”多样性”和”清晰度”似乎是GAN的 3大指标 — David 9
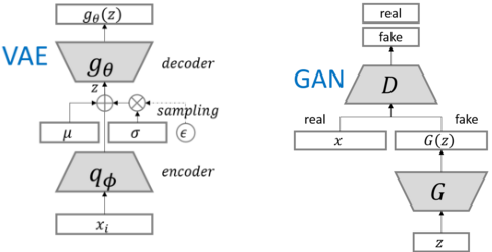
VAE与GAN
聊到随机样本生成, 不得不提VAE与GAN, VAE用KL-divergence和encoder-decoder的方式逼近真实分布. 但这些年GAN因其”端到端”灵活性和隐式的目标函数得到广泛青睐. 而且, GAN更倾向于生成清晰的图像:

GAN在10次Epoch后就可以生成较清晰的样本, 而VAE的生成样本依旧比较模糊. 所以GAN大盘点前, 我们先比较一下VAE与GAN的结构差别:
VAE训练完全依靠一个假设的loss函数和KL-divergence逼近真实分布:
![]() GAN则没有假设单个loss函数, 而是让判别器D和生成器G之间进行一种零和博弈, 一方面, 生成器G要以生成假样本为目的(loss评估), 欺骗判别器D误认为是真实样本:
GAN则没有假设单个loss函数, 而是让判别器D和生成器G之间进行一种零和博弈, 一方面, 生成器G要以生成假样本为目的(loss评估), 欺骗判别器D误认为是真实样本:
![]() 另一方面, 判别器D要以区分真实样本x和假样本G(z)为最终目的(loss评估):
另一方面, 判别器D要以区分真实样本x和假样本G(z)为最终目的(loss评估):
![]() 一般, 判别器D在GAN训练中是比生成器G更强的网络, 毕竟, 网络G要从D的判别过程中学到”以假乱真”的方法. 所以, 很大程度上, G是跟着D学习的.
一般, 判别器D在GAN训练中是比生成器G更强的网络, 毕竟, 网络G要从D的判别过程中学到”以假乱真”的方法. 所以, 很大程度上, G是跟着D学习的.
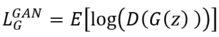{kind=link}
当然, 生成对抗网络也有一些问题, 比如经常很难训练(DCGAN试图解决), 有时候(特别是高像素图像), GAN生成图像不清晰, 还有时候, 生成图片多样性太差(只是对真实样本的简单改动).
这些问题, 催生出近年来各种有意思的GAN改进算法:
LSGAN(最小二乘GAN)
传统GAN中, D网络和G网络都是用简单的交叉熵loss做更新, 最小二乘GAN则用最小二乘(Least Squares) Loss 做更新:
选择最小二乘Loss做更新有两个好处, 1. 更严格地惩罚远离数据集的离群Fake sample, 使得生成图片更接近真实数据(同时图像也更清晰) 2. 最小二乘保证离群sample惩罚更大, 解决了原本GAN训练不充分(不稳定)的问题:
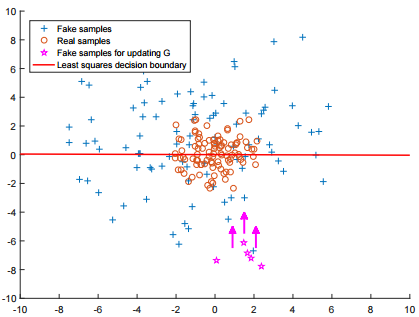
但缺点也是明显的, LSGAN对离离群点的过度惩罚, 可能导致样本生成的”多样性”降低, 生成样本很可能只是对真实样本的简单”模仿”和细微改动.
WGAN
DCGAN用经验告诉我们什么是比较稳定的GAN网络结构, 而WGAN告诉我们: 不用精巧的网络设计和训练过程, 也能训练一个稳定的GAN.
WGAN 通过剪裁D网络参数的方式, 对D网络进行稳定更新(Facebook采用了一种名叫”Earth-Mover“的距离来度量分布相似度).
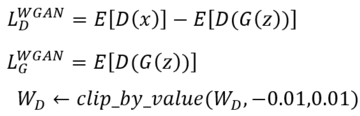
但是, 有时一味地通过裁剪weight参数的方式保证训练稳定性, 可能导致生成低质量低清晰度的图片.
WGAN-GP
为了解决WGAN有时生成低质量图片的问题, WGAN-GP舍弃裁剪D网络weights参数的方式, 而是采用裁剪D网络梯度的方式(依据输入数据裁剪), 以下是WGAN-GP的判别器D的Value函数和生成器G的Value函数:
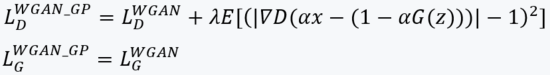
WGAN-GP在某些情况下是WGAN的改进, 但是如果你已经用了一些可靠的GAN方法, 其实差距并不大:

DRAGAN
DRAGAN本质上也是一种梯度裁剪(虽然文章自称是新颖的正则化方式),其判别器和生成器的价值函数类似WGAN-GP:
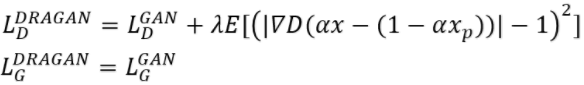 作者的初衷是希望避开局部最优解,获得更稳定的GAN训练。该算法另一个特点是实现简单, 作者提供的源码如下:
作者的初衷是希望避开局部最优解,获得更稳定的GAN训练。该算法另一个特点是实现简单, 作者提供的源码如下:
https://github.com/kodalinaveen3/DRAGAN
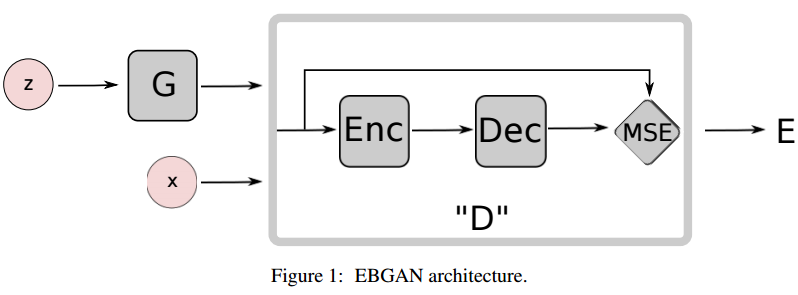
EBGAN(基于能量函数的GAN)
EBGAN我们在之前一期讨论过,EBGAN在边缘的生成效果上更流畅, 而且加了特殊的正则项, 在生成的类别上, EBGAN更倾向于生成不同的脸型和人种,下图是论文EBGAN和DCGAN的比较:

EGGAN的判别器比较特殊用了encoder-decoder的结构:
BGAN(Boundary-Seeking GAN)
BGAN优势在于生成离散样本(当然像图像这样的连续样本也可以支持)。
BGAN的生成器以不断生成决策边界上的样本为目标:
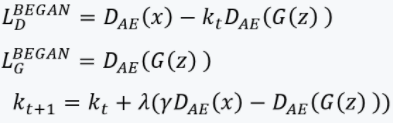 SGAN(Stacked GAN)
SGAN(Stacked GAN)
SGAN是一种结构创新的GAN,通过堆叠多个GAN网络,实现生成模型的信息“分层化”:
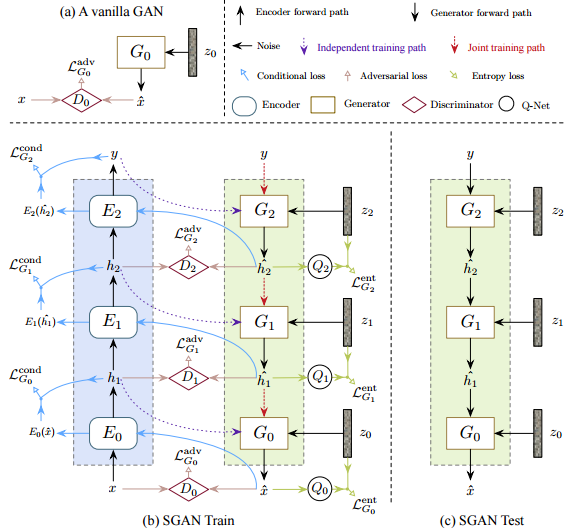
实验表明SGAN可以生成比一般GAN更清晰的图片 ,另外加入一些条件生成的功能也相当方便,github代码:https://github.com/xunhuang1995/SGAN
条件生成的GAN
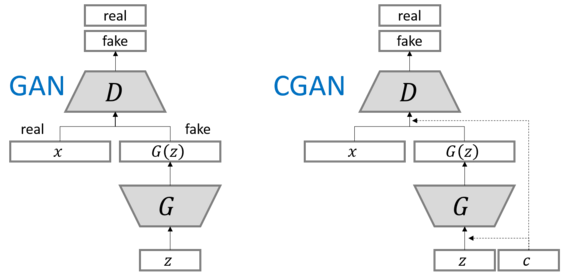
许多情况下,我们需要生成指定类的随机样本,这时就需要条件生成的GAN:
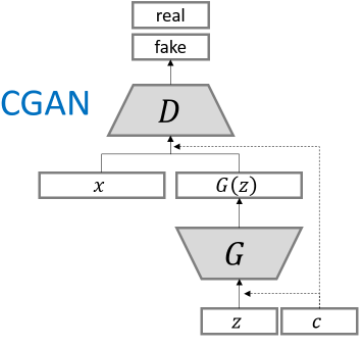
CGAN
CGAN是对条件生成GAN的最先尝试,方法也比较简单,直接在网络输入加入条件信息c,用来控制网络的条件输出模式:
 公式也相对简单:
公式也相对简单:
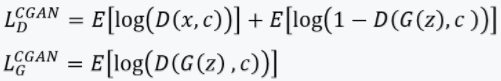
这样,使得生成指定label的样本成为可能:

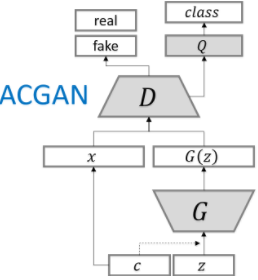
ACGAN(辅助类别的GAN)
ACGAN在Imagenet上的生成效果令人惊叹,它特意学习了一个类别下的图片结构:

与CGAN不同的是它在判别器D的真实数据x也加入了类别c的信息,这样就进一步告诉G网络该类的样本结构如何,从而生成更好的类别模拟:
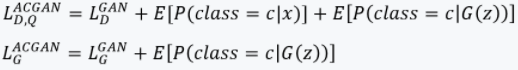
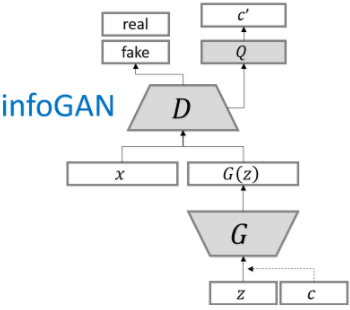
infoGAN
对于生成同类别的样本,infoGAN另辟蹊径,通过最大化互信息(c,c’)来生成同类别的样本,其中c是隐信息:
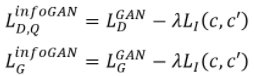
因为隐信息c可以作为超参数控制生成图像,我们可以得到一些有趣的结果:

如上图,通过控制隐信息c从-2到2,我们可以控制生成图片的旋转方向或者字体宽度(从左到右的每列)。
参考文献:
- https://github.com/hwalsuklee/tensorflow-generative-model-collections
- https://github.com/xunhuang1995/SGAN
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024