机器视觉是一场科学家与像素之间的游戏 — David 9
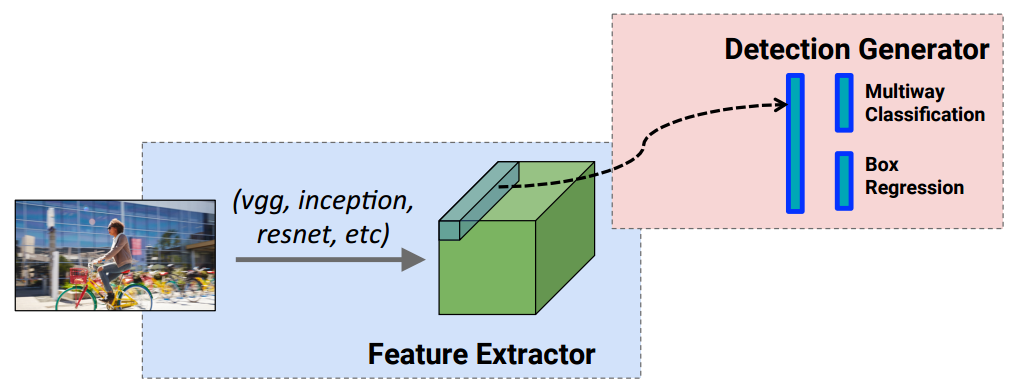
上一期,理解了YOLO这样的实时检测是如何”看一眼“进行检测的, 即让各个卷积特征图(通道)蕴含检测位置和分类置信度的信息(即下图的Multiway Classification和Box Regression):
 对于卷积的本质, David 9需要总结下面两点:
对于卷积的本质, David 9需要总结下面两点:
1. 单纯的卷积不会造成信息损失. 只是经过了层层卷积, 计算机看到了“更深”的图片, 输入图片被编码到最后一层的输出特征图(通道)
2. 较大的卷积窗口可以卷积得到的输出特征图能够看到较大的物体, 反之只能看到较小的图片. 想象用1*1的最小卷积窗口, 最后卷积的图片粒度和输入图片粒度一模一样. 但是如果用图片长*宽 的卷积窗口, 只能编码出一个大粒度的输出特征. 即, 输出特征图越小, 把原始图片压缩成的粒度就越大.
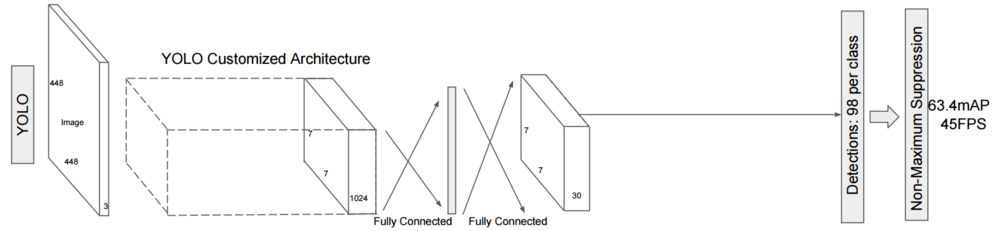
这也是为什么YOLO每层同样大小的卷积窗口, 识别超大物体或者超小物体就变得无能为力:
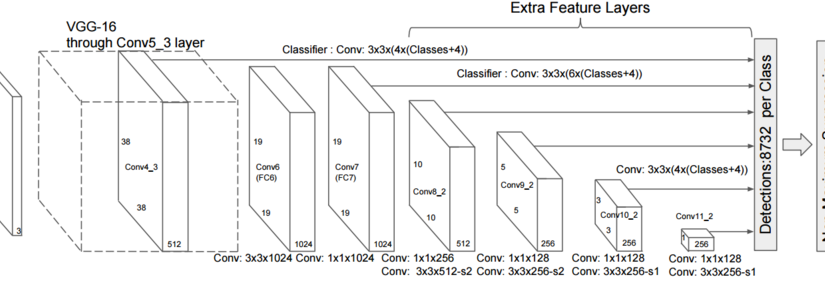
 YOLO最后一层的输出特征图是7*7 固定的, 因此只能检测到大小尺度相当的物体. SSD就此做了符合直觉的改进, 在最后7*7的输出特征后, 继续加一些不同大小的卷积层, 让最后这几层卷积同时为目标检测做出判断. 这样, 就可以识别各个尺度大小的物体(大物件或小物件):
YOLO最后一层的输出特征图是7*7 固定的, 因此只能检测到大小尺度相当的物体. SSD就此做了符合直觉的改进, 在最后7*7的输出特征后, 继续加一些不同大小的卷积层, 让最后这几层卷积同时为目标检测做出判断. 这样, 就可以识别各个尺度大小的物体(大物件或小物件):
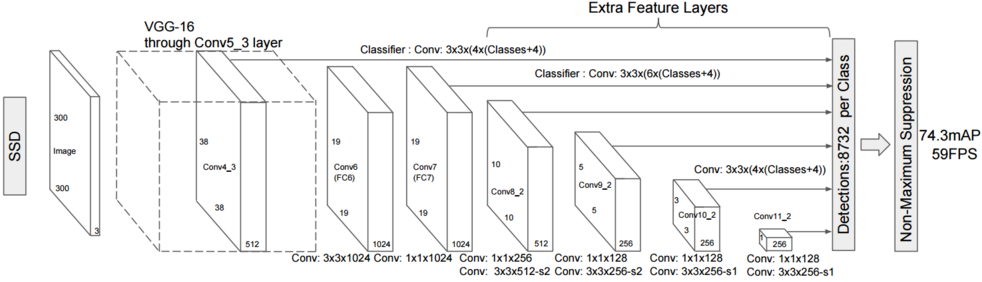
这样, 在8*8输出特征图中不能识别的大物体, 在4*4的输出特征图中就可以识别了:
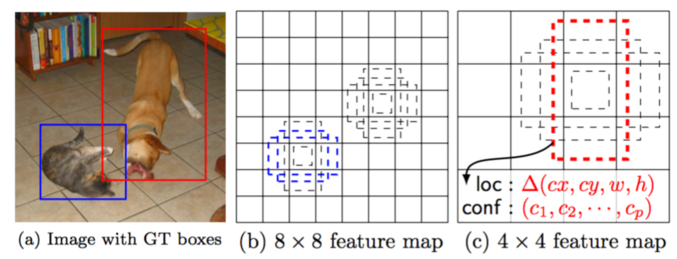
如上图, 原始图中的大狗在前一层8*8的特征图中不能被检测出, 而在后一层4*4的卷积中可以被检出, 获得了尺度上的灵活性.
与YOLO稍有不同的是, 为加大灵活性,SSD对每个cell有多个候选框(在SSD中称为锚Anchor或者默认盒子):
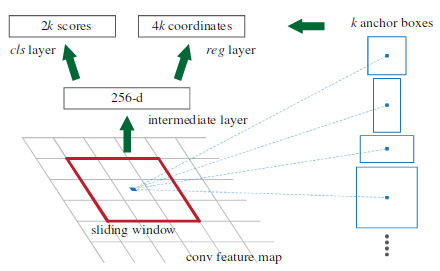 对于锚Anchor或者默认盒子, 模型会做出以下两个预测:
对于锚Anchor或者默认盒子, 模型会做出以下两个预测:
1. 对于当前anchor所属于的类别的预测
2. 对于实际物体位置的偏移offset的预测
最后,这些默认盒子在输出的特征图中被过滤后,得到最后的准确识别:
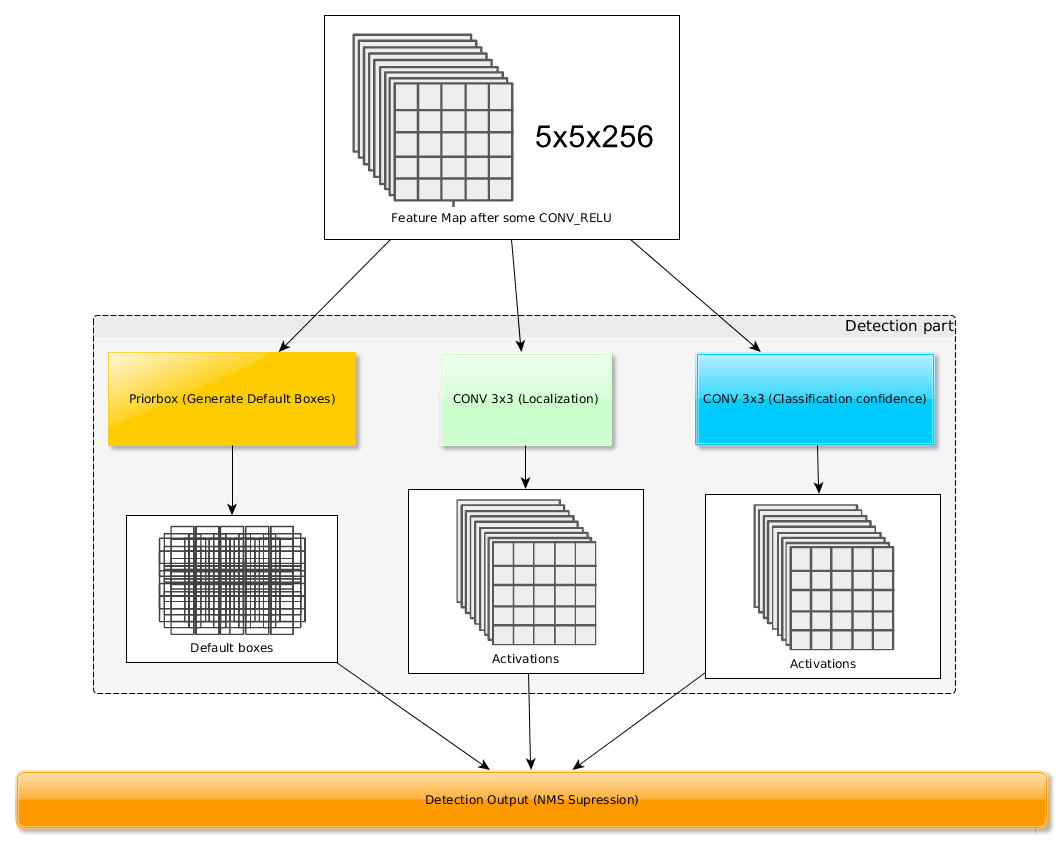
因此,SSD与YOLO的最大不同就在于如何把大小各种尺寸的物体都考虑到检测的范畴,并且有效地在相应的输出特征图上应用这些检测。
参考文献:
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024