从环境中获得显式(或隐式)的回报(奖赏)信息,强化学习(RL)是AI算法中最接近人真实生活的算法。正是由于这一点,强化学习可以简单到玩一个街机小游戏,也可以复杂到模拟并解释人类某个社会问题。此外,强化学习的tradeoff可以说是包罗万象,曾经我们聊过RL中对经验抽样的艺术,RL需要用恰当的方式从之前的路径经验中获得信息:
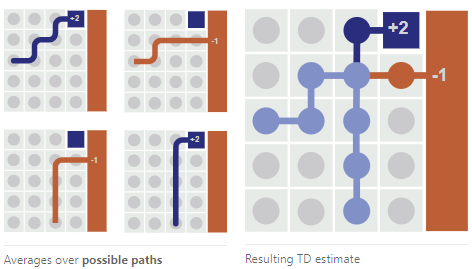
但是,岂止是权衡抽样。RL还要考虑回报是否稀疏(少经验少信息)的问题;angent(智能体)之间“合作”还是“竞争”的权衡went问题;还有RL训练低效,需要可迁移的经验和提高抽样效率的问题。只要是一个智能体面对开放复杂环境可以遇到的问题,强化学习都可能遇到。更宽泛地,还包括我们今天要聊的“扎根”和“开拓”之间的权衡(David这样翻译Exploitation vs Exploration)。
“Exploitation vs Exploration”是把握强化学习的一个重要角度。
假如你要选择今天午饭在哪吃,你是会选择以前去过的餐厅,还是去未知的新餐厅试试?这就是典型的“扎根”和“开拓”的困境:
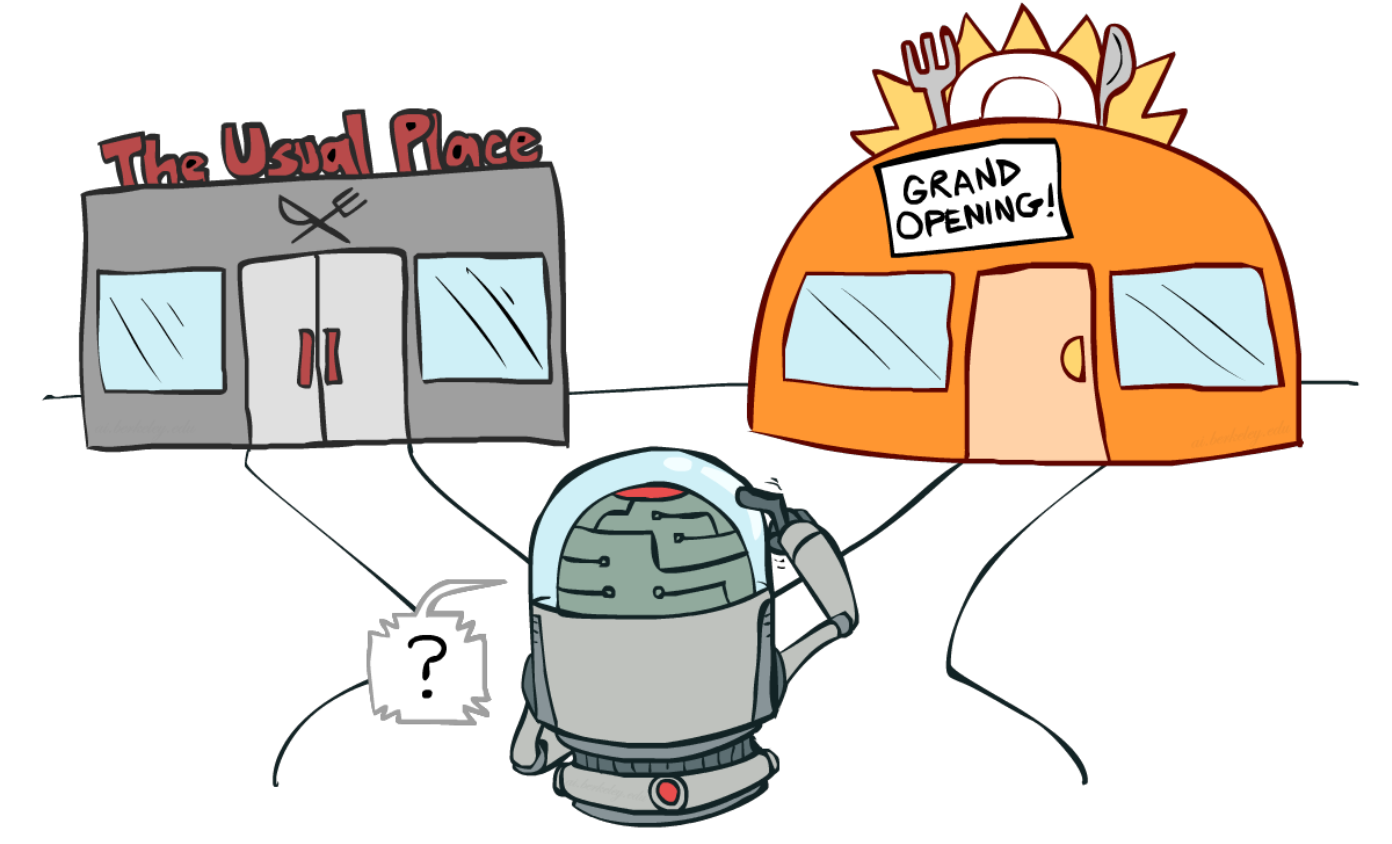
事实上如果经验足够丰富,“开拓”就变得不必要了,但是通常情况下,开放的外部环境比我们想象的大的多,所以,“开拓”的方法,以及在什么时间点选择“开拓”是必须考虑的。
并且,David需要强调的是,在实际算法和应用中,