
如果你要选验证集或测试集,就选那些你预料未来数据的样子(Choose dev and test sets to reflect data you expect to get in the future and want to do well on)— 吴恩达
前不久吴恩达新书“机器学习念想”(Machine Learning Yearning)手稿完工(不知道这样翻译会不会被打。。)David 9 忍不住拜读 ,把读后感总结如下,欢迎指正和交流:
纵观全书分三部分:
- 怎么构建验证集和测试集?
- 如何构建有效的性能和错误分析机制 ?如何优化模型?
- 端到端模型的一些讨论
事实上,上手深度学习(机器学习)项目最先要做的和模型本身关系不大,而是构思性能验证系统和错误分析的有效机制。
艺术品最华丽的可能是最后的润色,但其构思、规划以及推敲往往占据大师平时更多心力:

同样,构建一个高效的深度学习系统,首先要有一个好的验证体系、推敲整理过的数据集、高效的错误分析机制,这样最后的润色(模型优化)才能水到渠成。
1. 谈谈验证(测试)集怎么选?
书中建议是,如果你要选验证集或测试集,就选那些你预料未来数据的样子。因此训练集样本分布不需要和验证集(测试集)相同。用白话说就是以你预料“现场”的样本分布为准。
如果你在打造一个模型预测上海范围的车牌,那你的验证集就应该多选择“沪”牌(哪怕你的数据集有许多外地车牌)。

其次,验证集和测试集应该同分布,如果两者不同分布,集中注意在验证集上,而最后不知道测试集上的性能为什么差异巨大,给团队一个确定目标往往更重要(书中还建议把验证集分出一小部分重点关注集(eyeball dev set)指导模型优化)。另外70%训练集30%验证集对于非常大数据集不适用(一大锅好汤厨师尝一口就行无须喝掉1/3)。验证集的作用是探测出你对模型的改进。
另外模型是个强迭代的产品,为了提高效率可以找一个单一的度量指标去优化模型,哪怕准确率和召回率都要考虑,也可以求个平均值,以平均值(F1 score)为目标:

觉得验证集选错的时候也不要忘了更新验证集,不只是模型整个学习系统都要不断迭代
2. 如何构建有效的性能和错误分析机制 ?
如果你不是领域专家,不必一开始就精细地设计整个学习系统,可以从构建一个可用的“玩具”模型开始逐步优化(像达芬奇的素描)。构建一个重点关注集(eyeball dev set)指导模型优化,尽量使这个集合精简(这样你就可以随时人工查看分错的样本)
模型性能分析基本的两个概念是Bias和Variance(偏差和方差),偏差可以理解为训练集上的错误率e,方差是模型在验证集上的误差和刚才训练错误率e的差距(即训练错误率16%,验证错误率17%,那么方差就差了1%(我们知道模型在验证集表现总是比训练集差一点)。书中用大数据趋近的方式理解这两条学习曲线:
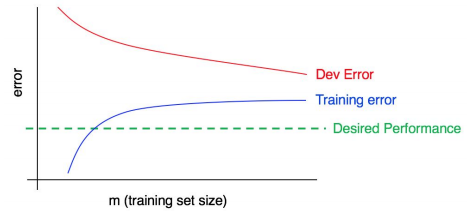
当训练数据集变大时(横坐标),训练错误率变大(根据大数定理越来越接近真实分布错误率);验证集错误率越来越小逼近训练错误率(同样可以用大数来理解)。其中假设绿色的线是最优的错误率,最优错误率和训练错误率的差就是不可避免的偏差(unavoidable bias)。验证集和训练集的差就是前面提到的方差(variance)。
那么如何降低可避免偏差和方差呢?文中也给出一些参考
降低可避免的偏差:
1. 增加模型复杂度,这可能会使方差增大,这时你可能需要增加正则约束
2. 做更仔细的特征工程,对输入特征人工优化
3. 去除已有的正则约束(有增大方差的风险)
4. 设计更好的模型结构(运气好可以同时降低偏差和方差 )
降低方差:
1. 增加更多训练数据(有时验证集错误率和训练集差距大只是因为训练集太小了)
2. 增加正则约束(有升高偏差的风险)
3. 对输入特征做人工删减和优化
4. 降低模型复杂度(有升高偏差风险)
5. 设计更好的模型结构(运气好可以同时降低偏差和方差 )
最后,由于现今大训练集获得变得容易,书中讨论了端到端(end to end)模型。如果你有非常大量的两端数据集,端到端模型的优势很明显:

如一个自动驾驶的方向控制模型,如果是端到端模型无须一些繁琐的人工特征筛选,模型会自动找到摄像头图片和方向盘转动的关系。但是如果数据量不够,其中某个环节可能很快成为瓶颈,这时其实一些手工特征或者拆分端到端模型效果也许更好:
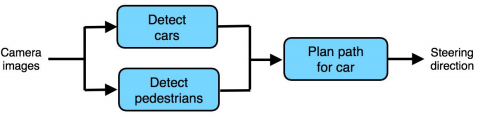
当把端到端模型拆分为多个模块时(识别汽车,识别行人,规划行车路线),也需要注意别让拆分的那些模型变成系统的瓶颈。拆分时尽量把单模型控制得简单。
参考文献:
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024