如果性能遇到了瓶颈,“老套”的办法总能帮我们搞定一些事情 — David 9
自深度卷积网络 广泛应用以来,我们更像进入了一个“伪智能”时代。深度网络的“创造”更多的是基于“巨量数据”的“创造”。以图片风格转换为例,无论是我们以前说的GAN还是其他变形CNN,都需要标注样本达到一定量,才能生成比较好的风格转换图(附带着冗长的训练时间 和其他模型调优技巧):

而英伟达前不久放出的CVPR新论文,一定程度上证明了在这个“伪智能”时代,只用深度网络是不够的,往往加入一些“老套”的算法可以帮你得到一些“漂亮”的结果:

上图是给定一张原始图片(a)和一张“黑夜”风格图片(b),我们希望把(a)的风格转换成(b)的结果。
可见(c)与(d)的结果都没有英伟达声称的方法(e)看起来自然。
而英伟达这篇论文的一大半贡献不在深度网络,
而是如何把传统的WCT(白化和调色转换:whitening and coloring transforms)应用到深度网络中,以及图片平滑的后处理工作。
整体框架如下:
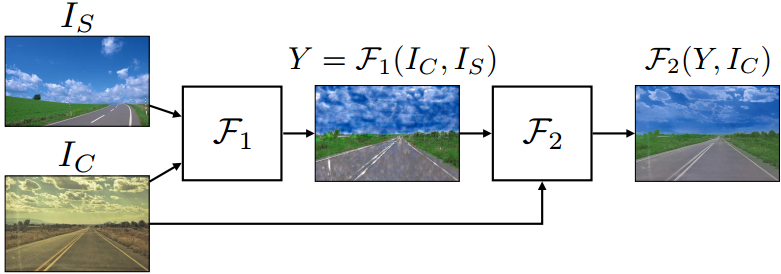
第一阶段F1即WCT操作,输入原始图片Is 和 风格图片Ic,输出的Y是经过WCT样式转换后的粗糙图片,图片质量较差不那么“自然”。
第二阶段F2,把粗糙转换后的Y对比原始图片Ic,进行图片平滑的后处理F2,获得最后的风格转换图片。
对于第一阶段F1有两个技术点:
1. 在自编码器最深的特征上使用WCT变换:
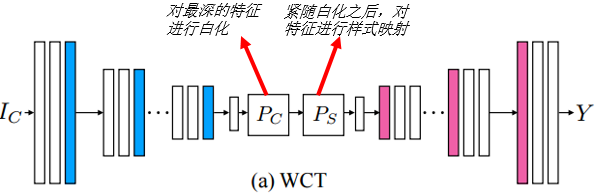
WCT的核心思想是把最深层的各个特征白化后(PC)直接映射须进行的调色操作(PS)。(如,一根夜光棒和一根普通棒子在黑夜的环境下表现是不一样的,前者会发光)
2. 自编码器的解码部分(decoder)中,使用上采样方法不能自然地还原图片,取而代之,用Unpooling层(反pooling层)进行解码:
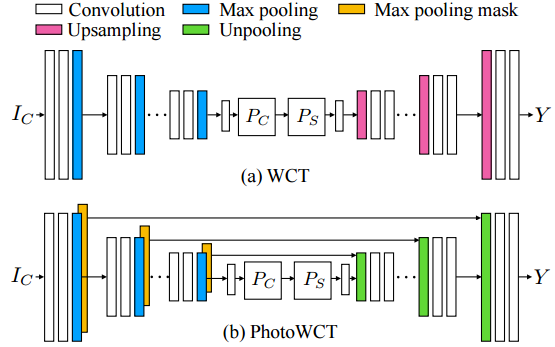
我们在胶囊网络一期中说过,pooling层很容易丢失一些有用信息,本文用Unpooling还原的方法更直接地把信息还原,而不是用上采样的间接方式。
这样还原的图片更真实,更少有失真和扭曲的情况:


对于第而阶段F2,主要是把图片做最后的平滑处理:
平滑处理的关键是:既要照顾到相邻像素之间需要连续的平滑性,也要照顾到图片整体风格的自然性。这两者的平衡靠参数 λ调整:

如果太关注全局,一些细节就展现不出来:
 如果太关注细节,图片就不那么自然:
如果太关注细节,图片就不那么自然:

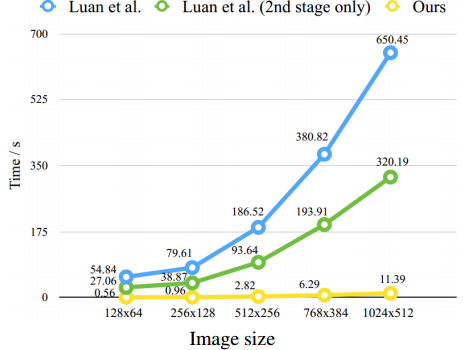
文章算法的另一个优势是运算时间较快:
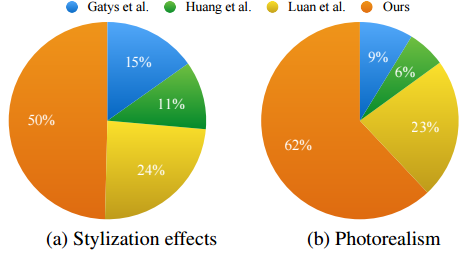
已经图片的真实性和自然度较高:
参考文献:
- A Closed-form Solution to Photorealistic Image Stylizatio
- https://github.com/NVIDIA/FastPhotoStyle
- https://github.com/Yijunmaverick/UniversalStyleTransfer
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024