看似庞大复杂的工程都来自一个简单的愿望 — David 9
人一生的行为往往由一个简单(但看似虚无)的意义驱动,而机器模型的行为由很多具体任务(实际的loss函数)驱动。于是,有的人为了“爱”可以苦费心思建成辉宏的泰姬陵 ; 而深度学习模型在不同任务间切换都如此困难。
幸运的是,多数人的愿望是AI朝着更通用(非具体)的方向发展。所以我们可期待更通用AI模型的出现。甚至David期待将来“域”通用模型的出现,这里的domain指的至少是人体五官胜任的所有任务(视觉域,语言域,音频域,触觉域,嗅觉域等)
拉回现实,OpenAI在语言域的GPT(GPT-2)和音频域的MuseNet模型已经取得了广泛关注。对于通用语言模型的探索,GPT早已不是先例:
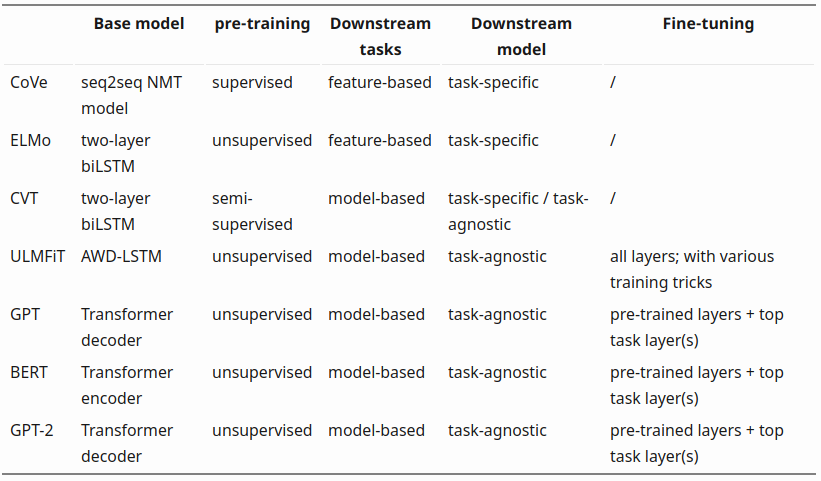
从汲取上下文关系的CoVe词向量(有监督,任务单一),到无监督预训练并且多任务通用的GPT-2 , 单模型“通用”的能力正在不断增强。
事实上,看似庞大复杂1.5B参数的GPT-2或GPT系列模型,背后的愿望非常简单:如何在模型不变的基础上,对于上层应用任务(Downstream tasks)通用 ?(模型层面通用)
GPT系列使用了预训练的语言模型+特定任务fine-tuning的方法做到这一点。
其中预训练是无监督的,对于语料中的一组tokens,去预测下一个token最可能的情况(其中u是预训练的语料):
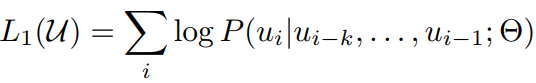
对于fine-tuning,把上一步中学到的大致语言模型,在用特别task的语料再针对地训练一遍(其中x,y是特殊task的语料):
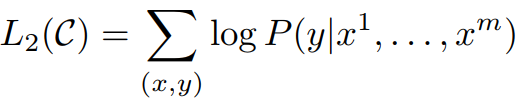
这一步是有监督的,确切场景下的语料。
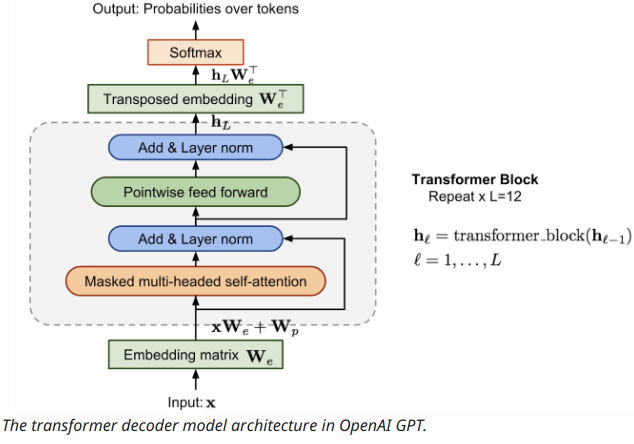
GPT总体模型架构如下:
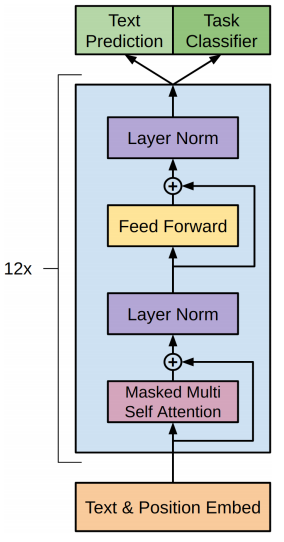
相比较Attention模型,GPT更加简洁,输入是文本和位置的词向量(Text&Position Embed),不像Attention模型还需要编码器(encoder),GPT直接用12层叫做转换解码器( transformer decoder )的块预测出之后单词(tokens)出现的概率。
当然,每层transformer decoder 都借鉴了Attention模型的机制,注意力机制使得模型知道自己在执行什么语言任务(文本分类?文本相似度识别 ?文本推断? 还是文本问答?)以及文本有更长的关注范围:
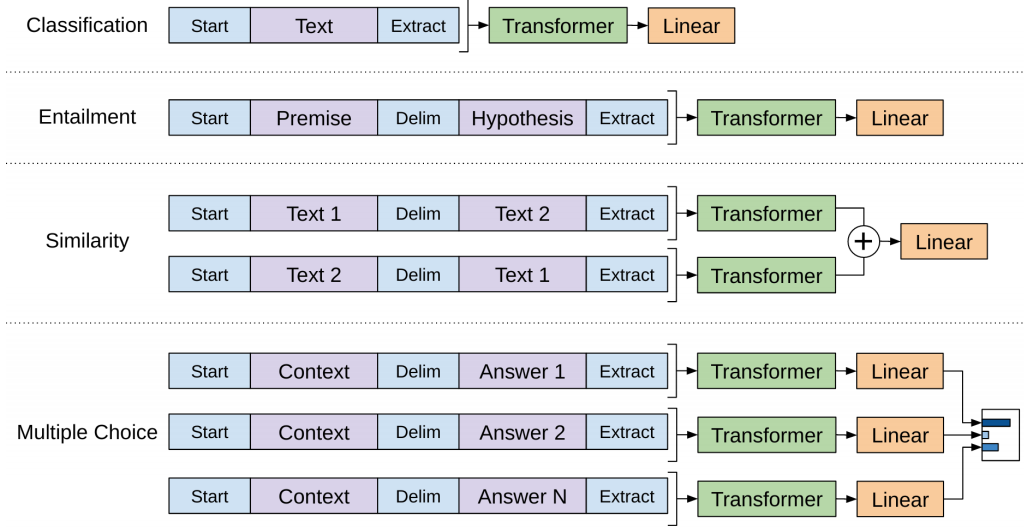
如上图,这些任务都用特殊的形式输入transformer decoder ,其实启始用“start”标注,结尾用“extract”标注,中间用“delim” 分割。这样注意力网络得到更好训练。
最后值得一提的是,这种通用的无监督技术在音频领域也有所应用,具体请看openai的MuseNet.
- https://openai.com/blog/musenet/
- https://openai.com/blog/sparse-transformer/
- 深度学习中的注意力机制(Attention Model)
- Improving Language Understanding by Generative Pre-Training
- Generalized Language Models
- https://github.com/openai/gpt-2
- Language Models are Unsupervised Multitask Learners
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024