前阵子Michael Kissner的神经网络Hacking教程似乎很火,现在David正好空下来聊一下神经网络的黑客攻防。看了一下目录都算简单易懂:

方法1,攻击神经网络权重weights
考虑一个简单的瞳孔虹膜安检系统模型:
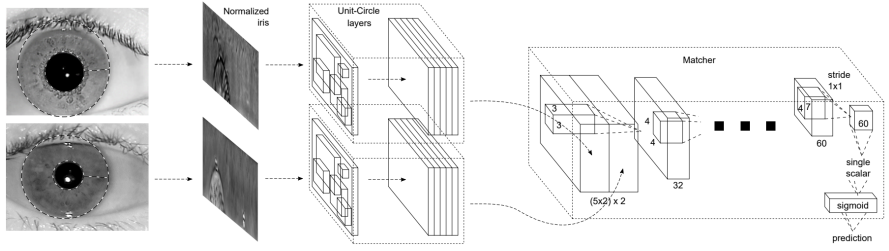
前几层是特征提取层,后几层是比对匹配层。如果你的想冒充CEO的瞳孔通过安检,你就需要有和他匹配的虹膜。让我们试想这样一种场景:你可通过某种途径拿到并篡改这个模型(假设是一个HDF5文件)。那么事情就变的相当简单,你用类似hdfview的工具修改HDF5文件,最直接地修改最后一层全连接层权重w,这样你可以马上得到想要的输出:
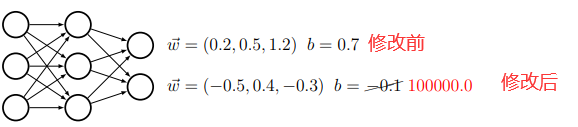
缺点与防范:
这种攻击过于粗暴,如果没有精心设计权重,很容易让对方察觉(模型异常)。另外,真实情况是很难有获得模型的并重写模型的机会。防范也比较简单,可以对模型文件做加密;可以限制模型“写”权限(防篡改);或者经常做模型更新和MD5校验。
方法2,神经网络后门攻击
这种攻击比方法1中“篡改权重”优雅一些。我们可以试图做到不修改原有神经网络的任何行为,仅仅加入自己的虹膜,让网络认为我的虹膜和CEO的瞳孔一致(嘿嘿,当然前提还是你可以篡改模型)。
有个小问题是,如果你没有瞳孔图像训练集,怎么重新训练模型再篡改呢?
Michael Kissner提了一个有意思的方法:
用小步长(learning rate),常用的loss继续训练少量你自己瞳孔的数据,让模型认为你的瞳孔是正样本。有点迁移学习的意思。这样模型原有行为变化很小,但你的瞳孔得到了通过。
缺点与防范:
依旧需要有修改模型权限。继续训练需要技巧:你不知道原本模型是用的什么loss和优化器训练的,你也要调整learning rate,难以验证原来的模型行为一切正常,如果导致别人的瞳孔验证失败,容易有嫌疑并引起注意。防范措施除了防篡改,还可以巧妙地使用变化的learning rate,自定义的loss,交叉验证,集成模型或拆分模型等。
方法3,信息提取攻击法
我们知道目前多数神经网络完全依靠反向传播,而反向传播恰恰暴露了网络曾经的“训练信息”,因此,
David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024