
想要释放模型的威力,可以尝试解放其输入的自由度,要知道,婴儿对外界各种形式信息从来都是来着不拒 — David 9
如果你没看到过老虎坐着的样子,但是你看到过其他小动物坐着的样子,你很自然地联想到老虎坐着应该是什么样子(如上封面图片所示)。
然而要让模型跨类转换图像,就没有那么容易,英伟达&&康奈尔大学使用的FUNIT模型的图像生成任务如下:
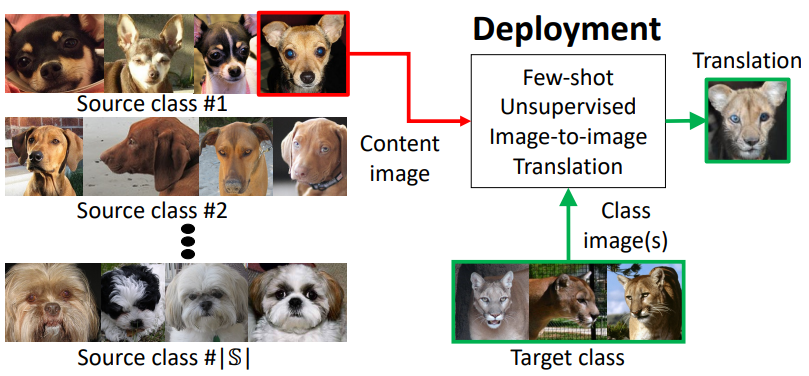
随意抽取一张原内容图片(Content image), 同时给出你想要转换到的目标类别(Target class),最后,需要由模型把原图片转换成目标类别的独特属性。如果你有一张小狗的图片,模型可以为你联想这只小狗“进化”成狮子会是什么样?
FUNIT训练框架如下:
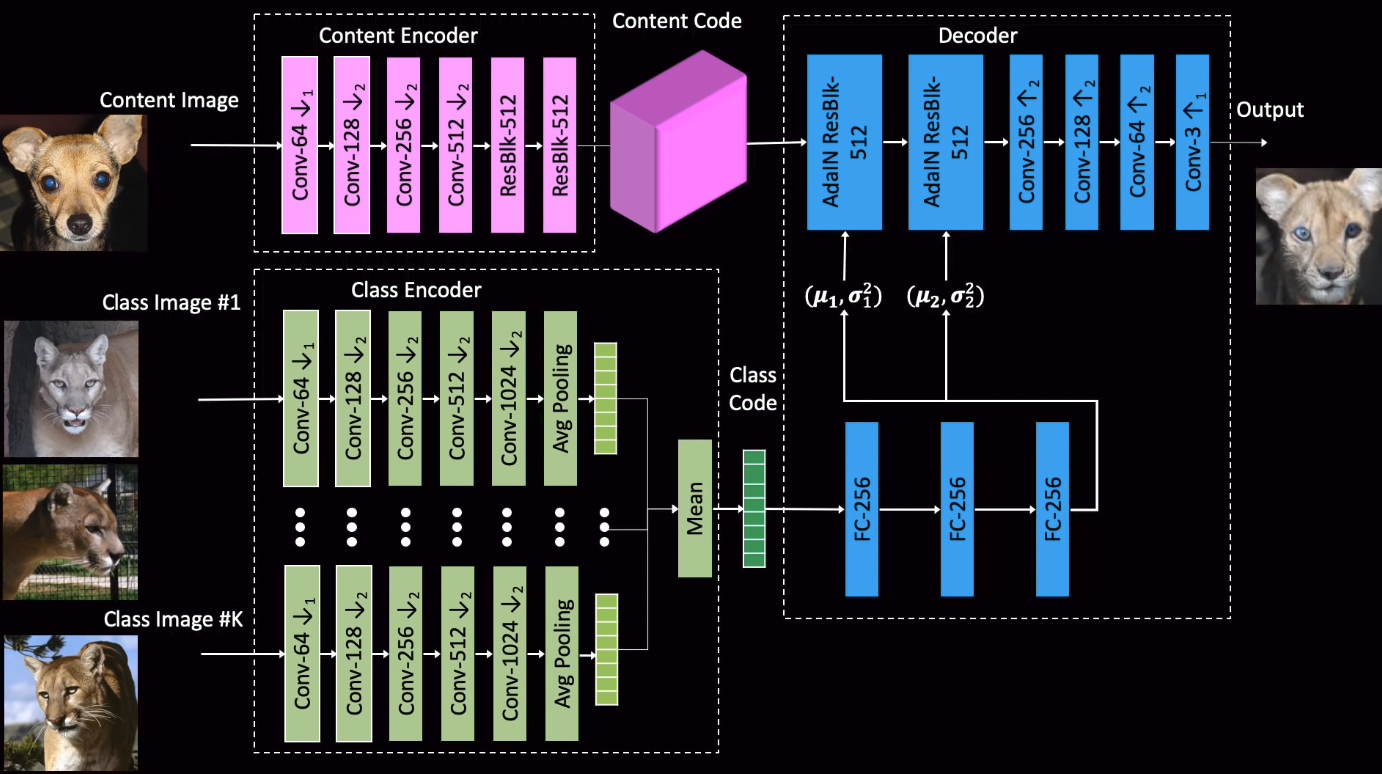
模型分3大块:内容编码器(Content Encoder), 类别编码器(Class Encoder)以及总解码器(Decoder)。当然,要通过这三个组件构造老套的GAN训练平衡,总的Loss函数如下:
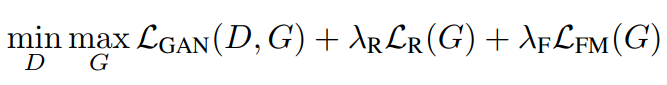
其中3项分别表示GAN的loss, 图像本身构图的loss, 以及特征匹配的loss 。
其中,
1. GAN的loss保证生成器和判别器之间的博弈,即,生成器竭力生成与目标类别相似的图像让判别器无法判断;判别器要竭力区分不同类别图片之间的区别。
2. 图像本身构图的loss保证生成的图像要像原图片的构图,即,转换后的图像要在内容上像转换前的图像(虽然类别性质明显不同)。
3. 特征匹配的loss用来给整个训练加上正则,保证生成的图像用cnn编码的倒数几层的特征值,与目标类别图像cnn倒数几层的特征值相似,即,生成图像与目标类别中的图像也都是相似的。
整个模型的源代码还没有完全公开,大家可以关注:https://github.com/nvlabs/FUNIT/, 有新进展可以联系David一起讨论成长。
参考文献:
- https://nvlabs.github.io/FUNIT/
- https://arxiv.org/abs/1905.08233
- https://www.youtube.com/watch?v=kgPAqsC8PLM
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024