所有高级的创造,似乎都有一些“搜索”和“拼凑”的“智能” — David 9
模型自动设计已经不是新鲜事(H2O 的AutoML,谷歌的CLOUD AUTOML)。但是,高效的神经网络自动设计还是一个较有挑战性的课题(单纯用CV选模型太耗时间) 。谷歌大脑的这篇新论文就提供了一种高效的搜索方法,称之为:Efficient Neural Architecture Search(ENAS)。
对于老版本强化学习的NAS,需要21天搜索出的cnn模型,ENAS只需要3小时就可以搜索出相同准确率的模型:
作者把这样的效率提高归功于候选子模型的参数共享上(相似子模型可以模仿迁移学习使用已有的权重,而不需要从头训练)。
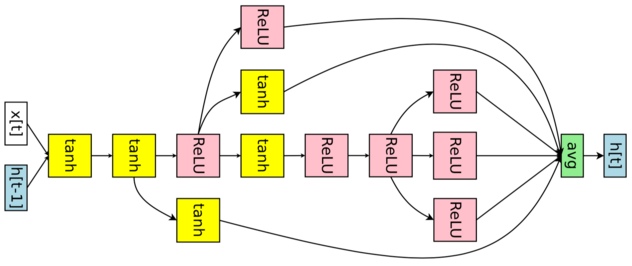
为简单起见,我们先从生成四个计算节点的RNN循环神经网络进行解释:
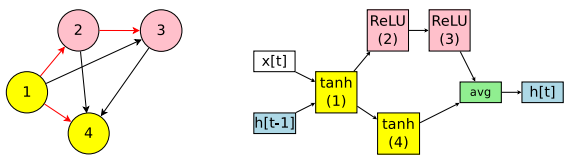
即使是只有四个计算节点的RNN,也有多种有向无环图(DAG)的生成可能,如上左图,红色的箭头生成的RNN才是我们在右图中看到RNN。
如何生成和设计上图RNN? 我们需要另一个被称之为Controller的RNN,注意,这是用来生成神经网络(理论上任何神经网络)的RNN:
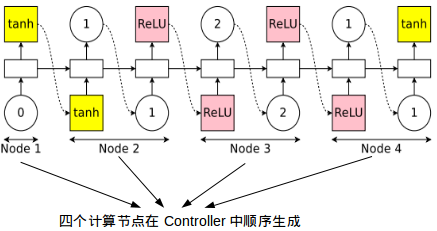
有了这个Controller,我们可以构建和改进神经网络架构。如上图,Controller本质上是一个RNN,如果输入计算操作(tanh,ReLU),它会返回下一个应该连接的节点下标(0,1,2);如果输入的是节点下标(比如节点2),它会告诉你这个这个节点的输出应该用什么操作处理(此处节点2后面应该跟ReLU).
有了生成模型架构的思路是不够的,我们还需要高效地评估Controller生成的子模型好坏:
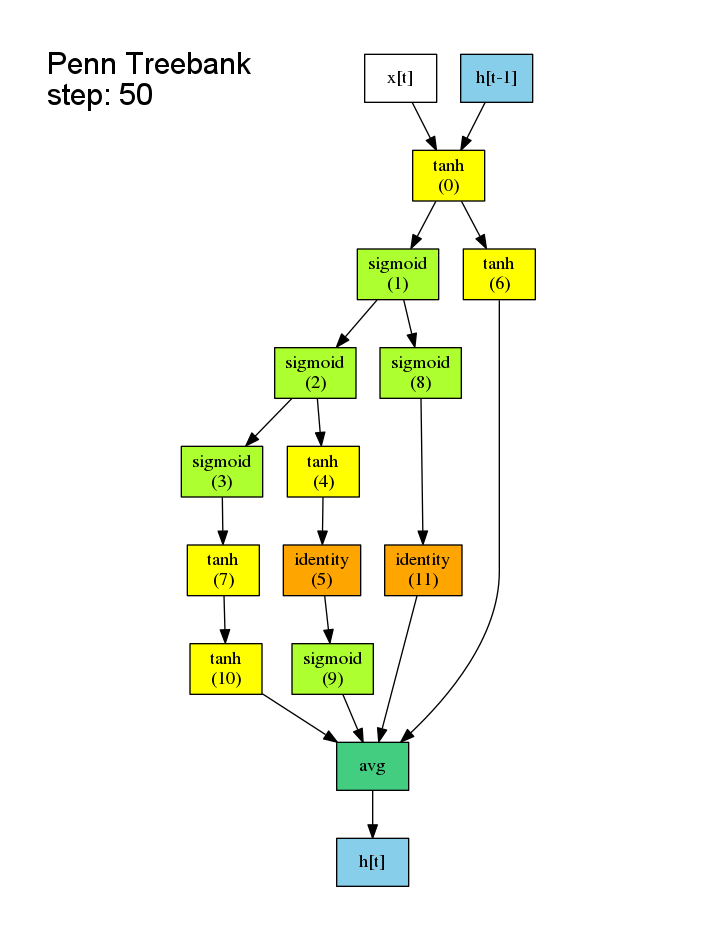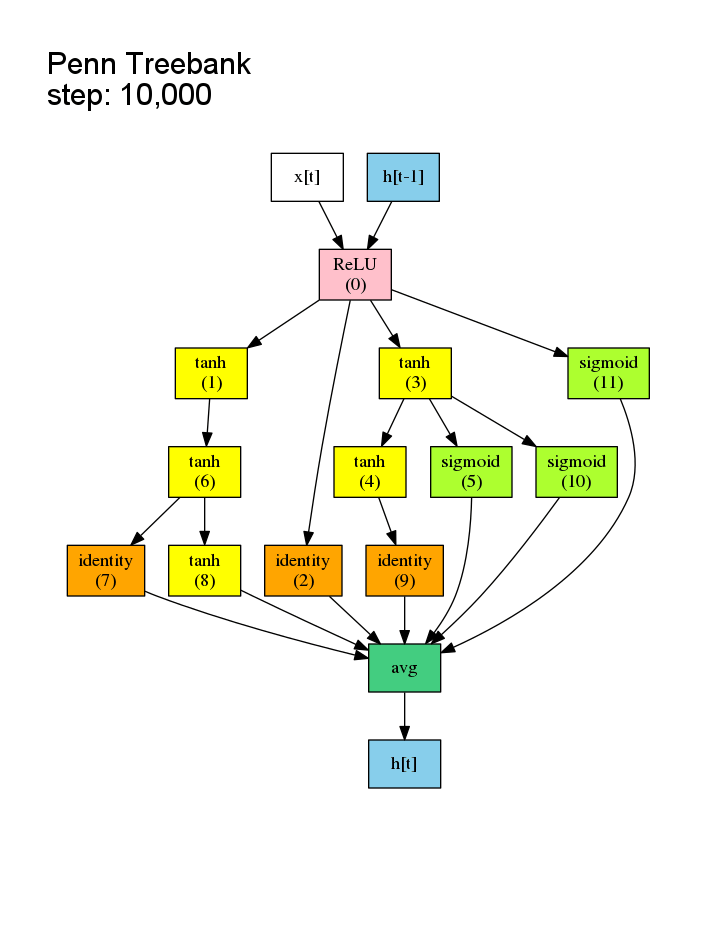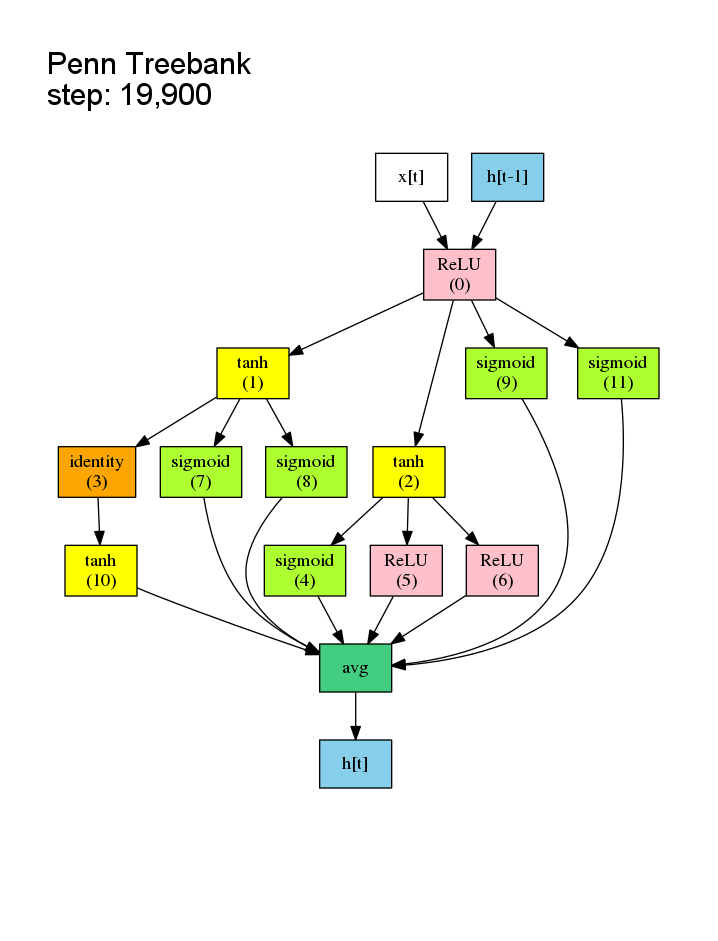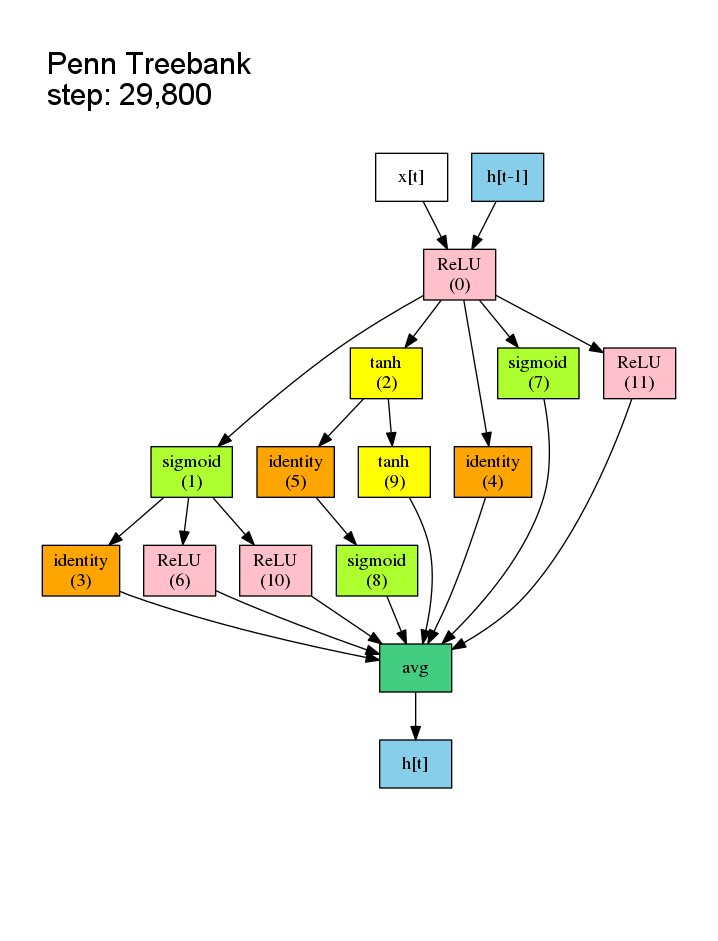
之前的NAS是对候选子模型逐个从头训练,事实上子模型的结构许多都是相似的,所以许多Wi,j (第i个节点与第j个节点的权重矩阵) 是可以复用的,没有必要从头开始训练。这样的共享权重在文中被称作shared model。
整个ENAS的搜索过程,是shared model和Controller交替更新的训练结果:
def train(self):
"""Cycles through alternately training the shared parameters and the
controller, as described in Section 2.2, Training ENAS and Deriving
Architectures, of the paper.
From the paper (for Penn Treebank):
- In the first phase, shared parameters omega are trained for 400
steps, each on a minibatch of 64 examples.
- In the second phase, the controller's parameters are trained for 2000
steps.
"""
if self.args.shared_initial_step > 0:
self.train_shared(self.args.shared_initial_step)
self.train_controller()
for self.epoch in range(self.start_epoch, self.args.max_epoch):
# 1. Training the shared parameters omega of the child models
self.train_shared()
# 2. Training the controller parameters theta
self.train_controller()
if self.epoch % self.args.save_epoch == 0:
with _get_no_grad_ctx_mgr():
best_dag = self.derive()
self.evaluate(self.eval_data,
best_dag,
'val_best',
max_num=self.args.batch_size*100)
self.save_model()
if self.epoch >= self.args.shared_decay_after:
utils.update_lr(self.shared_optim, self.shared_lr)
上述代码是ENAS Pytorch的实现,
1. self.train_shared() 在模型架构固定的情况下,基于训练集,更新和共享内部参数权重Wi,j,使得内部权重得到更好收敛。
2. self.train_controller() 充分使用共享的内部权重,从controller RNN中抽样出一些候选子模型,在这些模型中选择在验证集上表现最好的架构,继续步骤1的计算。
以上两步交替进行,即ENAS的主要搜索过程。其中共享权重的代码似乎在shared_rnn.py中有所体现:
self.w_h = collections.defaultdict(dict)
self.w_c = collections.defaultdict(dict)
for idx in range(args.num_blocks):
for jdx in range(idx + 1, args.num_blocks):
self.w_h[idx][jdx] = nn.Linear(args.shared_hid,
args.shared_hid,
bias=False)
self.w_c[idx][jdx] = nn.Linear(args.shared_hid,
args.shared_hid,
bias=False)
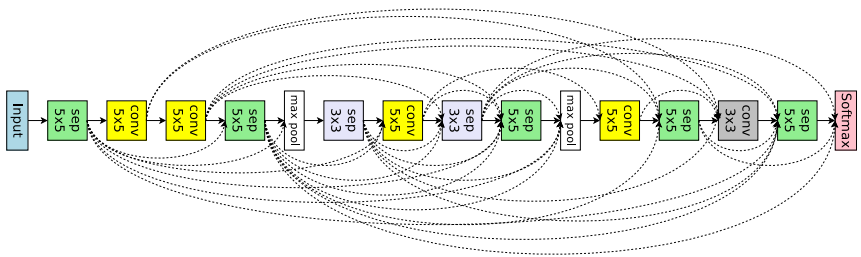
上面是RNN神经网络架构生成的实现,在CNN神经网络中,会更复杂一些。
首先,CNN中会有一些跳层连接,因此1个节点可能会连接2个之前节点:
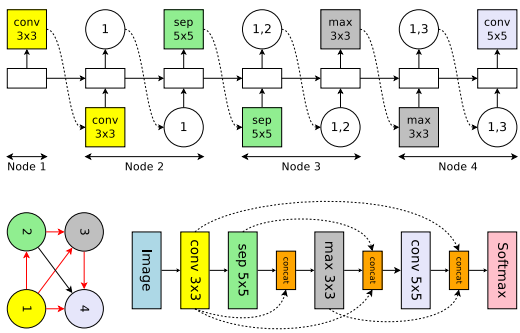
上图的sep指的是可分离卷积(Separable Convolutions)如果对可分离卷积及其他卷积不熟悉,可以去这个链接补补:An Introduction to different Types of Convolutions in Deep Learning
其次,目前的CNN架构中经常遇到卷积块的内部设计,文中称之为micro search(如inception网络中的block,以及Separable Convolutions):
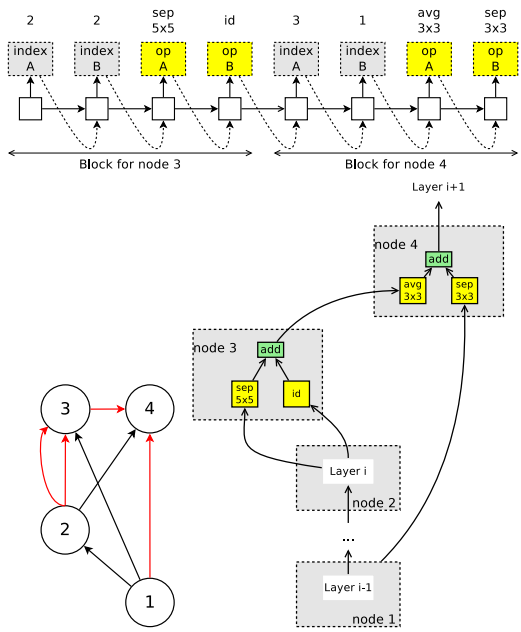
最后,我看看在CIFAR-10数据集上ENAS与其他算法的综合比较:
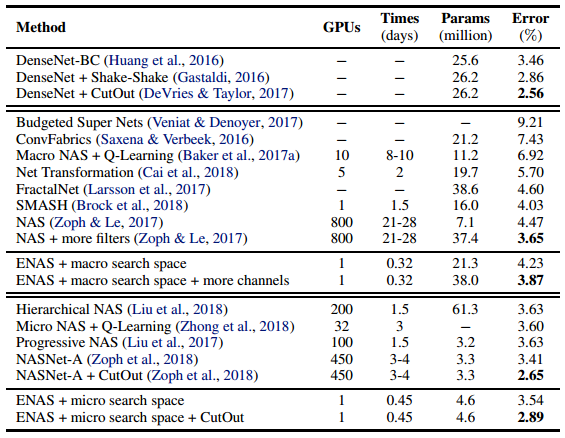
可见ENAS算法时间效率上的搜索优势较大,而准确率上,DenseNet+CutOut的人工网络设计最佳。
参考文献:
- Efficient Neural Architecture Search via Parameter Sharing
- https://github.com/carpedm20/ENAS-pytorch
- https://github.com/melodyguan/enas
- An Introduction to different Types of Convolutions in Deep Learning
- https://zh.wikipedia.org/wiki/%E8%B0%B7%E6%AD%8C%E5%A4%A7%E8%84%91
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024