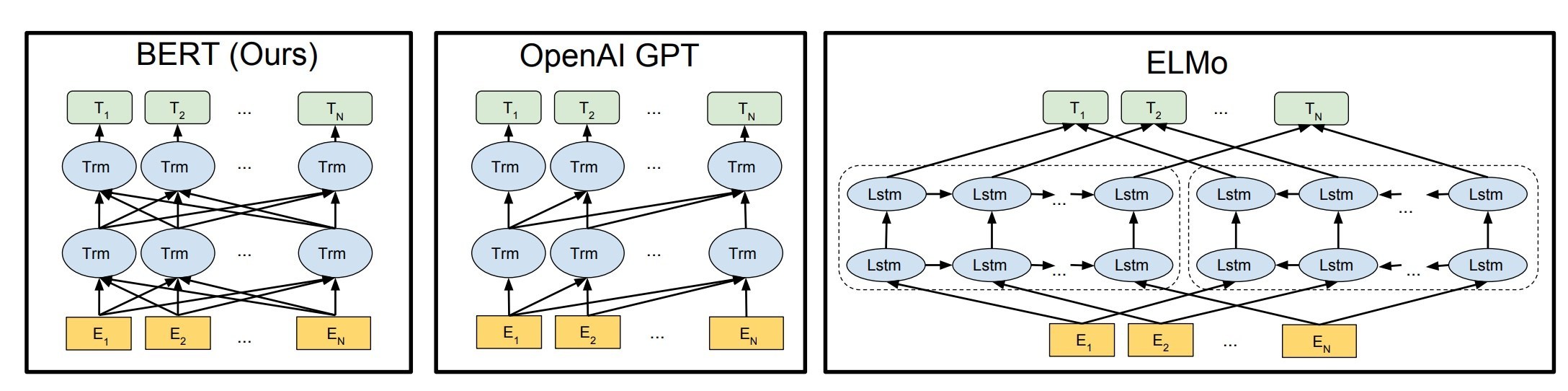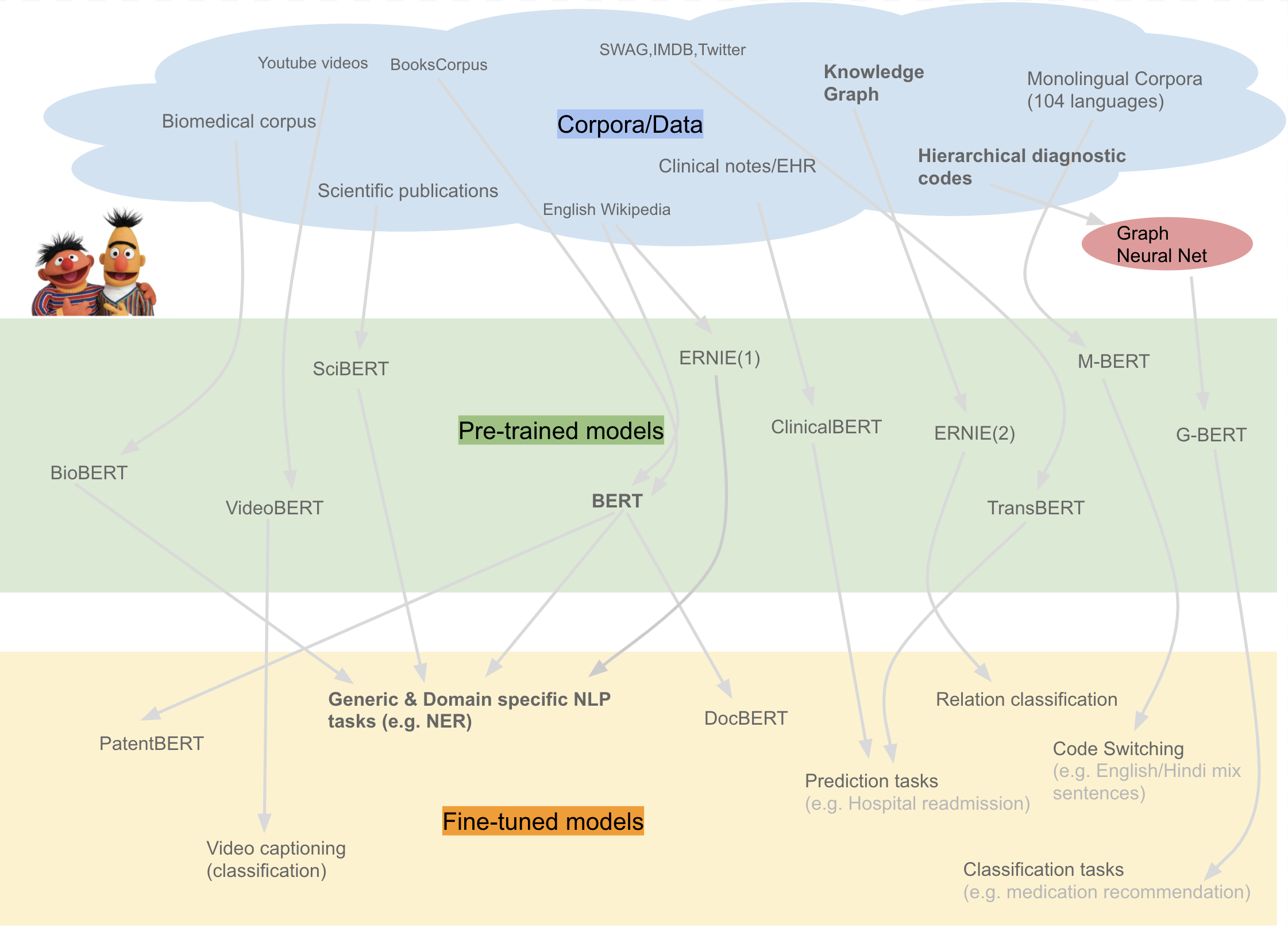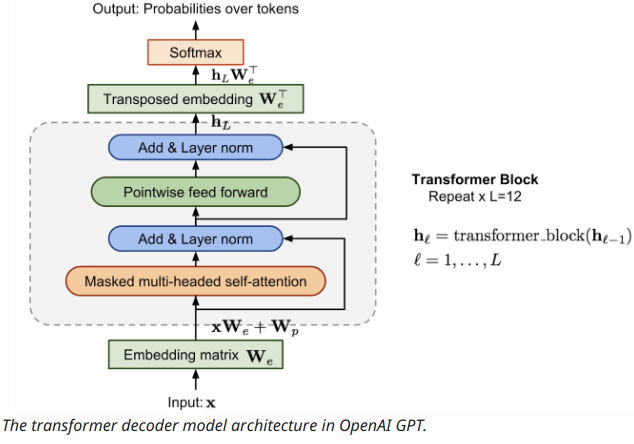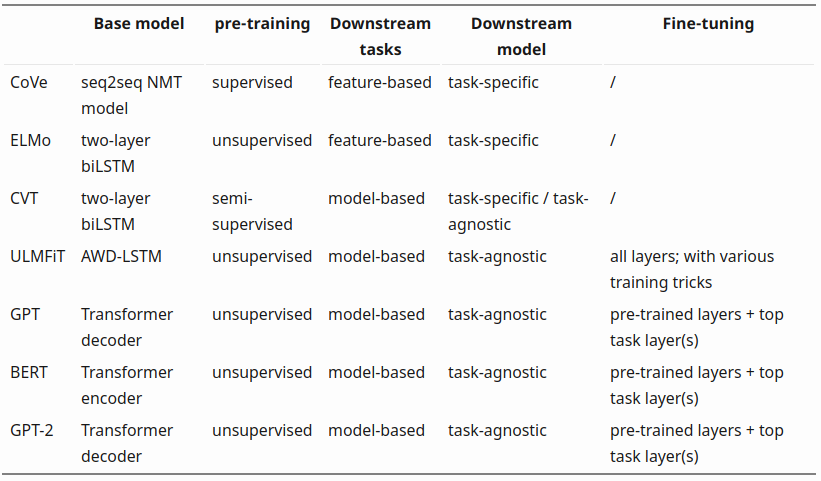
也许技术也存在“明斯基时刻”,
当那些“侵蚀”变为“颠覆”——David 9
因为人类是“感知”(欠理性)的动物,所以那些用“思潮”的力量影响(或鼓动)别人的人,也许才是最“可怕”的,其中也包括技术浪潮,神经网络和Transformer并没有那么神奇,但它们就像雪山顶上最高的那团雪球,却越滚越大,把周围的雪吸拢进来。
多数创新,是之前无数的“侵蚀”和修改积累而来的,但是就是有一些“颠覆”的创新,让你相信一切可以从头开始,一切变得会很不一样!但其实,我们也许只是达到另一个阶段而已。
就像许多论文喜欢杜撰一个“不一样”的名字,比如今天聊的“lambda神经网络”,目前在ICLR2021预审中表现不错,让我们看看它有什么“不一样”,
就David的观察和ykilcher的视频分析,lambda神经网络是对注意力机制的完善改进之一,而不是“颠覆”性的,但其中聪明的技巧值得我们学习,我就ykilcher的视频分析展开讨论:
首先,目前现有的Transformer改进都是基于原有的短板(长序列难支持,计算量大,速度慢等)的改进。lambda神经网络也不例外,
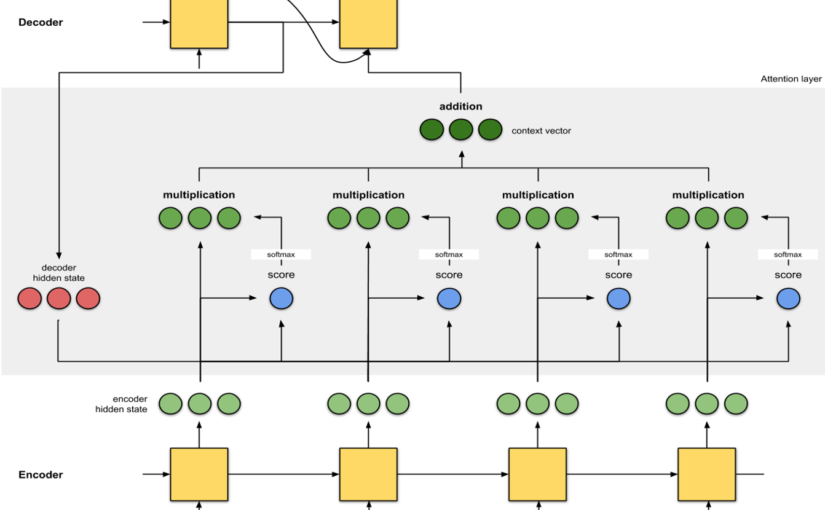
众所周知,注意力机制(Transformer的核心),直白说,是把一组序列,映射到另一组序列,而中间的矩阵,就是负责映射(包含权重)的注意力矩阵:
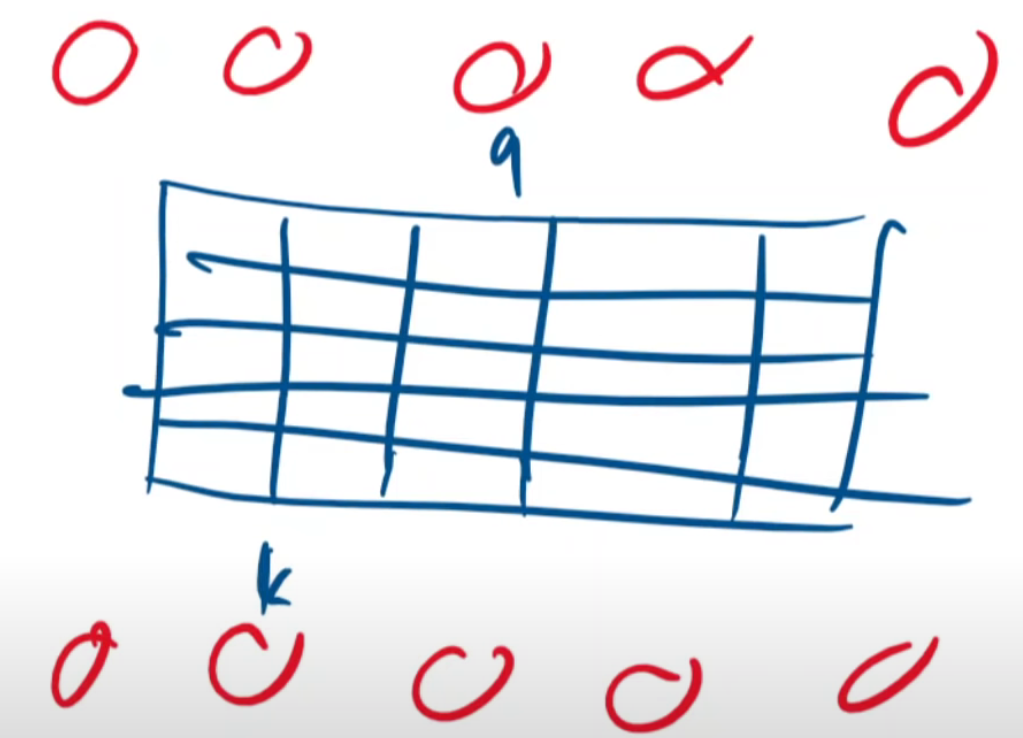
其中,k和q就是注意力机制中的key,query,试想,如果输入序列非常长, 继续阅读ICLR2021【lambda神经网络】Transformer模型虽被改得面目全非,看似的“颠覆”更多是“侵蚀”,#局部注意力和特征提取