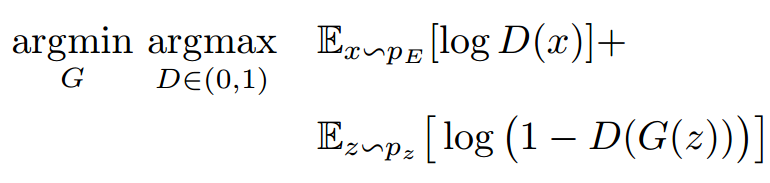人类在做其他看似不相关的事情时,会给手头的任务带来灵感; 模型也应如此,让它在训练时做其他任务,会对它的实际预测带来好处(正则约束) — David 9
多任务模型David不是第一次讲了,但是之前涉及的是强化学习或自然语言领域。在视觉领域,多任务学习就更有意思了。自动驾驶是该领域的常见应用,不但要求准确率99%+,极低延时,而且是一个开阔的“无限游戏”,正如特斯拉AI负责人Andrej Karpathy在ICML2019发言上提到的,其复杂性是多方面的,
遇到的车况可能很复杂:

摄像头的视觉角度也很复杂(8个方向):

更复杂的是,自动驾驶天生就是多任务的:
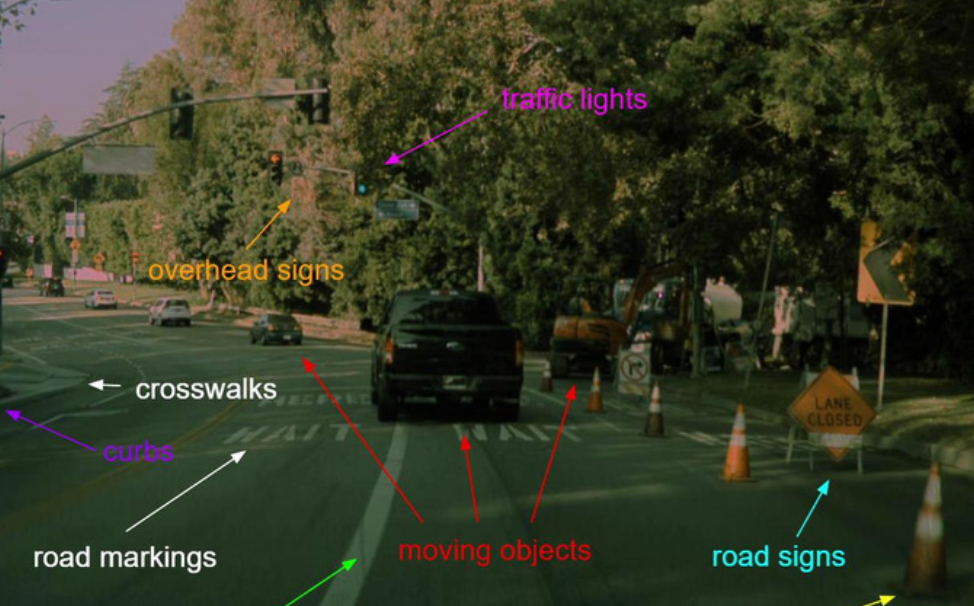
在你开车时,你的眼睛和大脑要同时分析移动的车辆,静态的路灯,斑马线,路标,警示牌,等等。。。甚至loss函数的设计都是复杂的,因为一些任务就是比一些任务更重要(我们要重点关注突然闯红灯的行人)
要适应如此复杂多变的环境并且要求实时导航,如何去建模真的很有挑战性。首先,你不可能对每个任务都建一个模型:
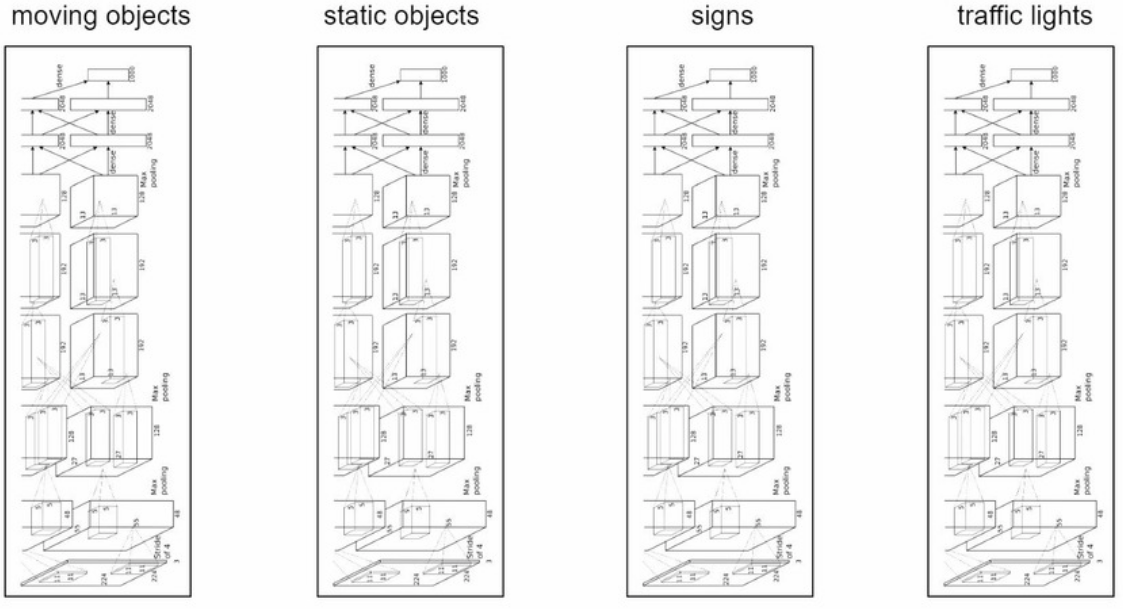
这样哪怕可行开销也太大(除非你想多送用户几块gpu或硬件资源)。另一个极端是所有任务都合并为一个模型: 继续阅读David9的ICML2019观察:Tesla自动驾驶建模是如何搞定多任务学习的?实时多任务,autopilot自动导航