虽然ICLR2018将在今年5月召开,但是双盲评审已经如火如荼。目前评审结果排位第一的论文试图解决神经网络在预测分布上缺乏鲁棒性的问题。
我们都知道神经网络和人一样也有判断“盲点”。早在2015年Ian Goodfellow 就提出了攻击神经网络的简单方式,把cost函数 J(θ, x, y)对输入图片x求导,得到一个对神经网络来说loss下降最快的干扰噪声:

一旦加入这个细微噪声(乘以0.007),图片的分错率就达到了99.3% !
这种生成对抗样本的攻击方法被称为FGM(fast-gradient method快速梯度法),当然还有许多攻击方法, 下面是对数字8的测试攻击样例:

有了攻击方法我们就能增加神经网络的鲁棒性, 那么FGM是加强模型鲁棒性的最好参考吗?
该论文的答案是:NO !
论文提出了Wasserstein鲁棒更新方法WRM,文章指出,通过WRM训练出的模型有更鲁棒的训练边界,下面是David 9最喜欢的论文实验图:
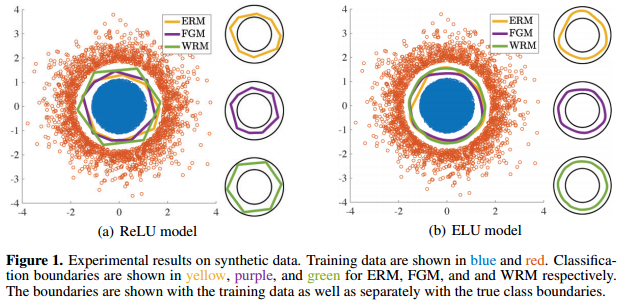
杰出的论文不仅应该有实用的方法,更应该有让人豁然开朗的理论,不是吗?
上图Figure 1是一个研究分类边界的人工实验,蓝色的样本点和红色的样本点是两类均匀样本,因为蓝色样本比红色样本多得多,所以分类边界倾向于向“外”推。 继续阅读ICLR2018抢先看!深挖对抗训练:提高模型预测分布的鲁棒性, Wasserstein鲁棒更新方法WRM,以及Earth Mover’s Distance