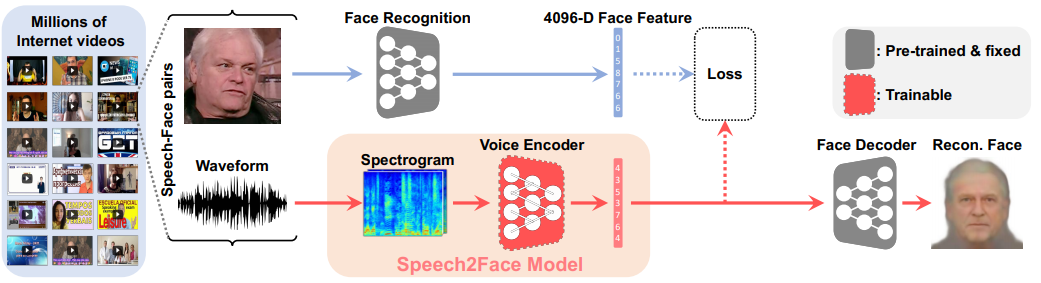
作为无监督无配对图像的样式转换领域的标杆,CycleGAN让人印象深刻。通过一个循环一致loss(cycle consistency loss) 保证生成器生成的样本经过再生成,能够和原来样本保持相似一致性:
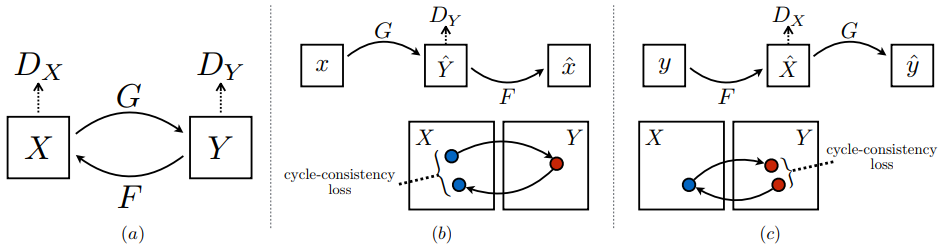
所以,生成器不仅要像普通GAN那样生成另一个样式域的图像,而且,这个生成的图像如果从另一个样式域映射回来,要和原图足够像才行:

但是CycleGAN也有缺点,CycleGAN不可能针对所有样式转换应用都适合,所以针对特殊应用需要修改,另外,这种双向GAN loss计算量就比较大,两个样式域的loss都要考虑。
针对这些,EnlightenGAN在训练夜景增强,低曝光还原的图像上试图更近一步:

事实上,CycleGAN和EnlightenGAN都是在loss上做了手脚(你必须告诉GAN要生成和原图相似的图像,不是吗?)。
但EnlightenGAN 更进一步 ,做到了单向GAN训练(无需cycle循环): 继续阅读对标CycleGAN:EnlightenGAN是如何无监督(无配对图像)训练夜景增强,低曝光还原的?