来自deci.ai的专家提了一些不入俗套的训练模型的建议,david觉得不错,分享给大家,如果你每天还在机械化地调整模型超参数,不妨看看下面几个建议:
1) 使用指数滑动平均EMA(Exponential Moving Average).
当模型容易陷入局部最优解时,这种方法比较有效。
EMA 是一种提高模型收敛稳定性,并通过防止收敛到局部最优来达到更好的整体解的方法。— Shai Rozenberg
它是这样工作的:
- 令 W_m 为执行优化步骤后的当前权重集
- 在下一个优化步骤之前复制这些权重
- 取刚刚复制的权重和上一步的权重的加权平均值
- 更新当前步骤,加权平均
公式大致如下: 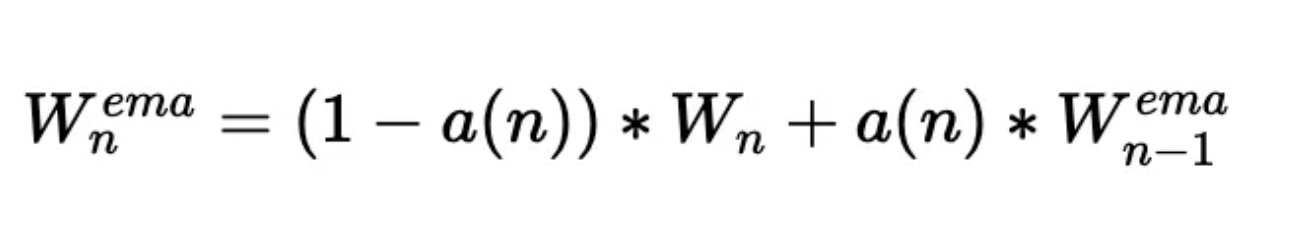 2) 权重平均
2) 权重平均
每个人都喜欢免费额外的性能提高。
加权平均可以达到这一点。当然,训练N个模型再平均他们的权重开销比较大。另一种更节省成本的方式是,把比较好的那些epoch的模型拿出来做平均,这样只要训练一次,又能达到意想不到的效果。
3) batch积累
如果有一些模型训练开销很大,而且需要的GPU显存又很多,你不得不降低batch size达到训练的目的。然而,和原来训练代码配套的超参数似乎就要重新调整了? 继续阅读如何不入俗套并像专家一样训练模型? —— David9的打趣帖子


