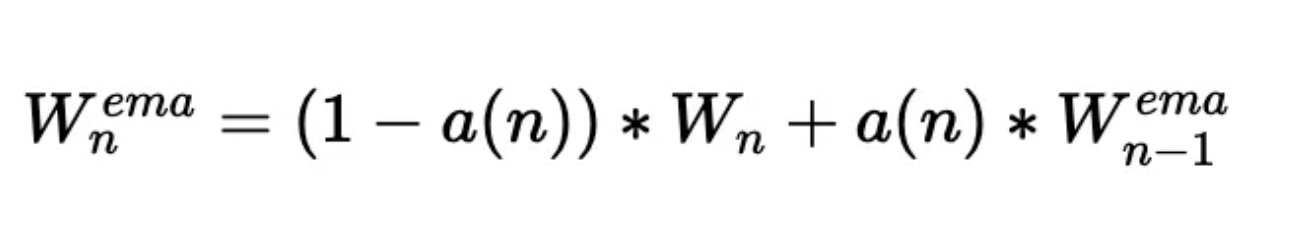如果要保持某个发明是黑盒状态,人类必须保证其不停的发展,这几乎是不可能的 —— David 9
人们有两个重要的动机把一切新工具看做白盒去研究:1. 如果工具出了问题,从内部机制寻求解决是常规的方法,2. 每个人都有信心认为自己的见解比别人独到,所以如果这个工具是一个黑盒,一定是之前没有很好地被理解。
神经网络也是这样一种工具。并且白盒化过程在视觉模型中尤为明显,近期的两个项目很好地反映出这个过程。
其一是yolov9视觉检测模型的PGI(Programmable Gradient Information)可编程梯度信息改进。
信息瓶颈原理指出,随着网络的深度加深,图像在网络传播的过程中不可避免地会有信息损失,输入与输出的互信息会不断减小:
当然,把模型的参数量变大可以缓解这种问题。但依旧不能很好地解决:

yolov9为了更好地解决上述问题,PGI主要由三个部分组成:(1)主分支:用于推理的架构,(2)辅助可逆分支:生成可靠的梯度,为主分支提供后向传输,(3)多级辅助信息:控制主分支学习可规划的多级语义信息:
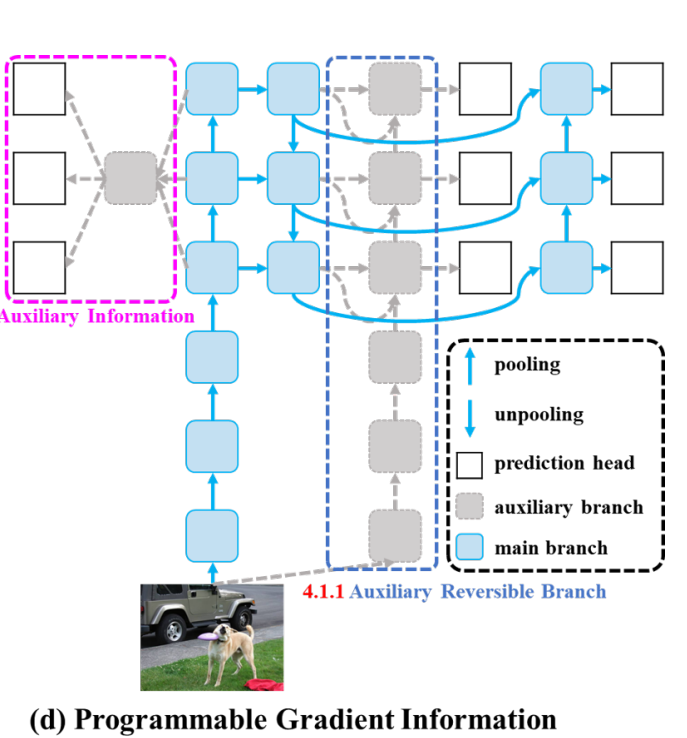
这些辅助的分支在训练时需要,但预测阶段并不需要,因此,可以理解为在训练阶段的一种“特征矫正工程”,但和一般眼科矫正不同的是,它更像一种植入矫正技术,在特征生成的每一层都有“植入”。
另一个令人印象深刻的项目 继续阅读修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流?