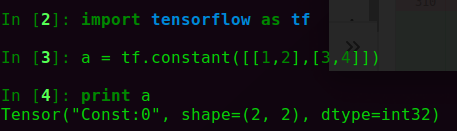
David不经常聊代码,之所以单独post这篇文章,实在是这三种创建模型的方式很有代表性。市面上所有深度模型框架,在创建模型时,也不外乎这三种方式:
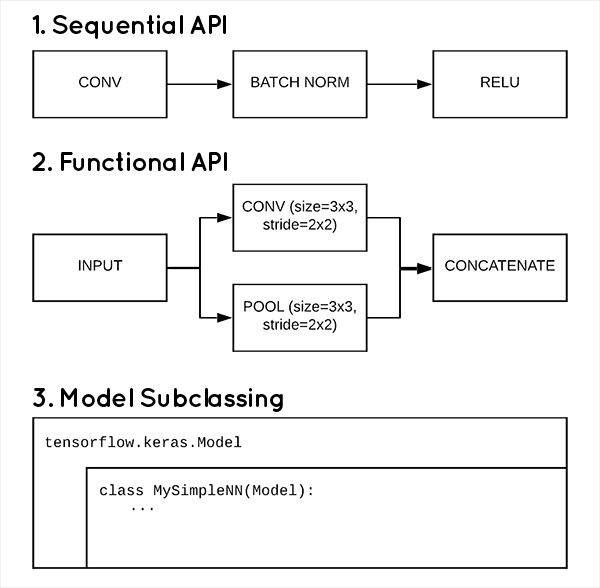
第一种,序列模型。这是Keras最简单的构建模型方式(也许是所有框架中最简单构建方式),它顺序地把所有模型层依次定义,可以共享层的定义,多输入输出,但是如果要有分支,自定义层,就很困难了,下面是一个简单例子:
def shallownet_sequential(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" ordering
model = Sequential()
inputShape = (height, width, depth)
# define the first (and only) CONV => RELU layer
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
# softmax classifier
model.add(Flatten())
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
在Keras中只要模型是Sequential类,那就是使用了序列模型。
第二种,函数式模型。熟悉函数式编程的朋友对这种方式很好理解,即一切定义都是基于函数的。这种方式给了自定义层的更大空间,可更简单地定义层的分支,合并(concatenate)等, 继续阅读3种用Keras和TensorFlow2.0创建模型的方法:序列模型,函数式模型和继承子类模型