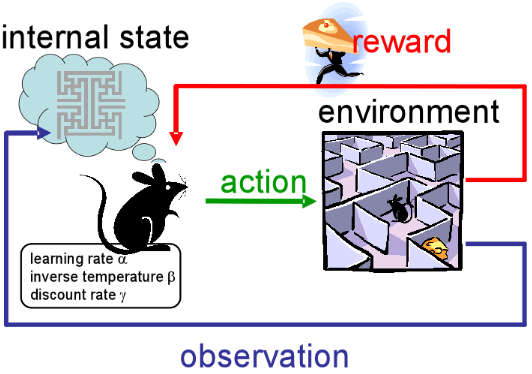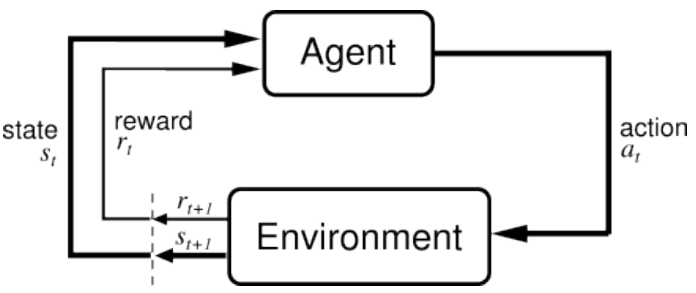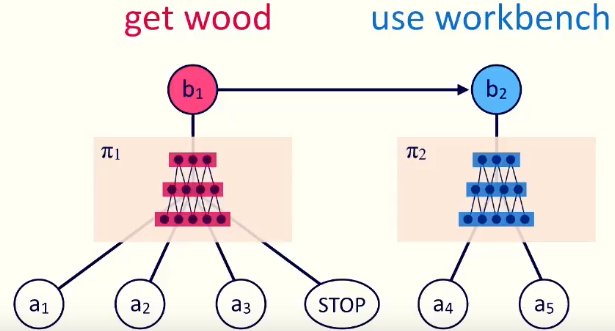
人类日常行为中自觉或不自觉地总结抽象的”套路”, 以便将来在相同的情况下使用. 分层的增强学习正是研究了在较高的抽象任务中, 应该如何看待以前总结的”套路”, 并且如何在较低层的行为中使用它们. — David 9
正如我们之前提到过, 深度神经网络的迅速发展, 不会阻碍类似增强学习这样的高层学习框架发展, 而是会成为高层框架的重要底层支撑.
今年ICML最佳论文提名中的一篇(Modular Multitask Reinforcement Learning with Policy Sketches), 正是属于分层增强学习: 用”策略草稿“进行模块化的多任务增强学习.
说的通俗一点, 就是教会神经网络学习在各个不同的任务中总结通用的”套路”(或者说策略草稿,行为序列):
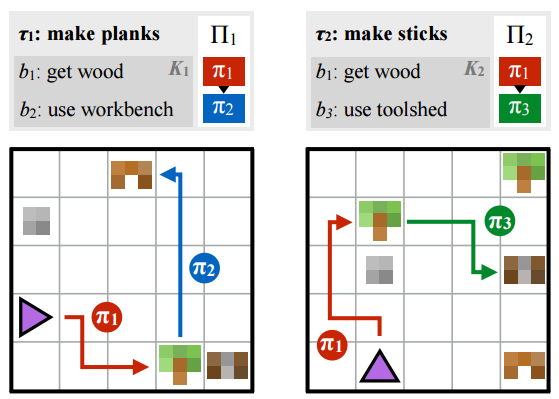
上图左右两图, 分别代表两个高层任务(“制作木板”(make planks) 和 “制作木棍”(make sticks)). 事实上, 这两个高层任务的完成, 都需要一个子策略π1的必要条件, 即 : 我们需要首先拿到木材 ! 继续阅读ICML 2017论文精选#2 用”策略草稿”进行模块化的多任务增强学习