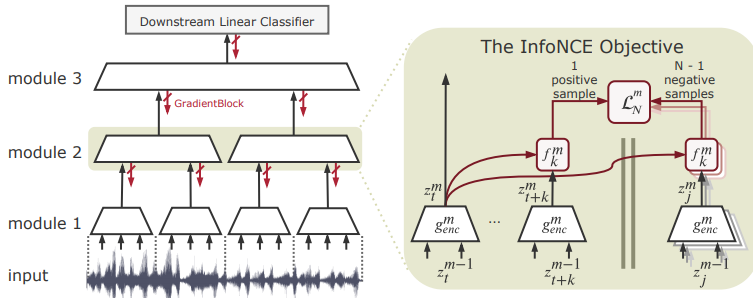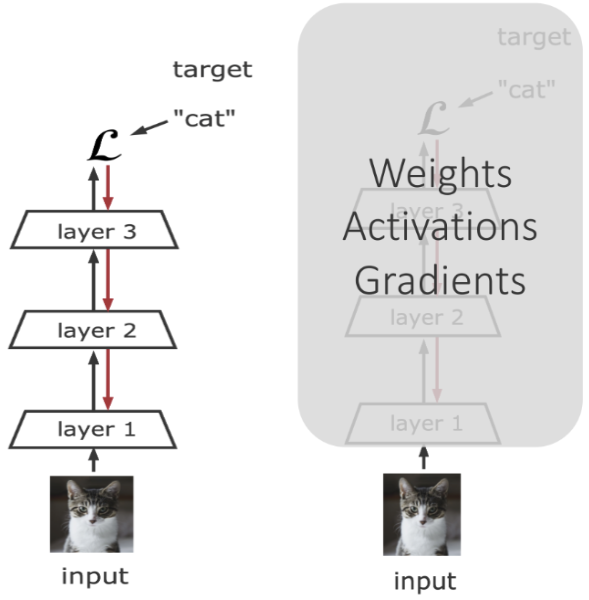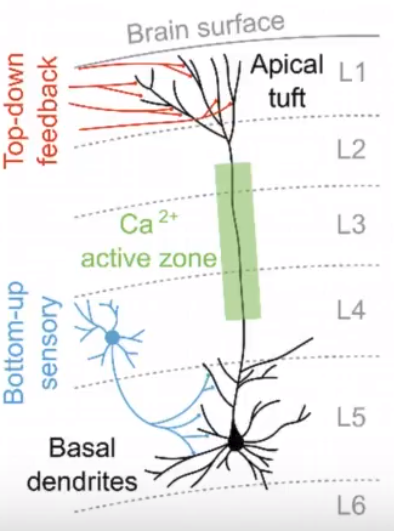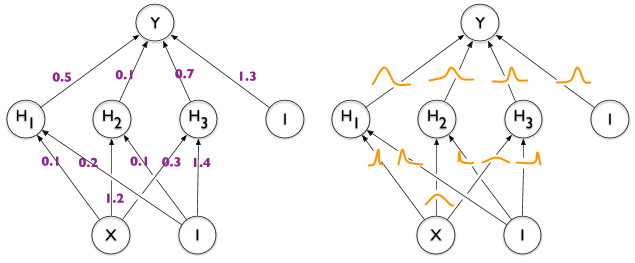
一个“大”的未来,总是要有一个“大”的期望 —— David 9
如果你还不清楚贝叶斯理论中先验与后验的关系,David做个直白的比喻:如果你是天文学家,那你需要选用望远镜观察,然后记录数据,最终做出预测。这个过程中,你选用的“望远镜”就是“先验”,而你“记录数据”的过程就是“后验”,两者共同决定你的预测质量:

所以在用贝叶斯推断时(或变分推断时),如果先验(望远镜)选不好,后验估计(观测者记录)再好也是徒劳。当然,让一个外行人记录观测也是不靠谱的(失败的后验估计)。
这样,如果我们用贝叶斯思想去审视神经网络,你会发现它的“先验”无处不在,包括:
网络架构 (宽的网络还是深的网络?用resnet那样跳层还是inception那样分组?) ,
网络组件(内部用卷积还是类似rnn的记忆单元?选用什么方式防止过拟合?BN?Dropout?),
loss函数 (loss函数包含了你评估模型的核心先验,它在训练时深刻地影响了模型的收敛方向),
这些都是人为预先设置的“先验”(无论你是否察觉)。
什么是神经网络的“后验”估计呢?广义地说,整个神经网络的训练过程就是“后验”估计的过程。 传统地,我们用SGD梯度下降逼近模型的最优解,它帮助我们在庞大的数据中寻求后验估计
 那么重点来了,贝叶斯神经网络(BNN)和这种一般神经网络 继续阅读贝叶斯神经网络(BNN)靠谱吗?BNN的基本思想, 它的未来在哪里?
那么重点来了,贝叶斯神经网络(BNN)和这种一般神经网络 继续阅读贝叶斯神经网络(BNN)靠谱吗?BNN的基本思想, 它的未来在哪里?