如果你的思考足够抽象,并赋予抽象非凡的意义,AI很难赶上你 — David 9
最近看的Keras作者François Chollet访谈,David我也是他的粉丝,
如果说特朗普是twitter治国的,也许他就是twitter治AI的了,下面这推就表示了他对目前AI学界的深深担忧😁😁😁:
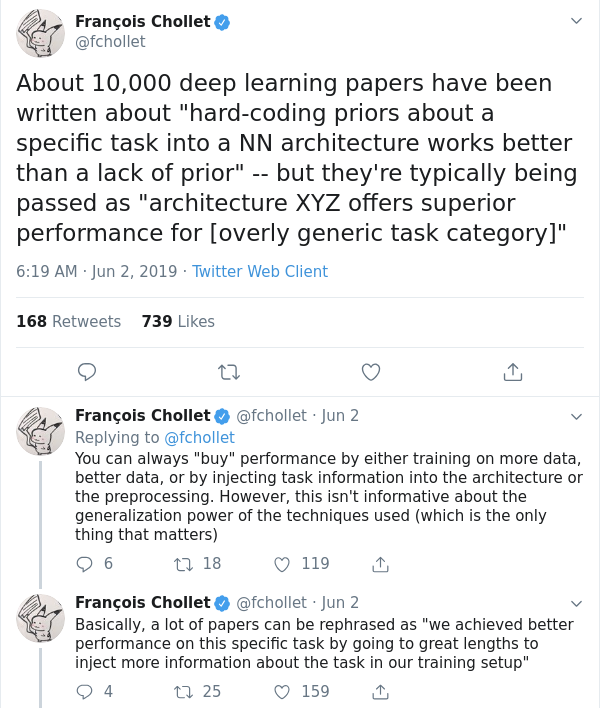
是的,大多数深度学习论文本质上借助的是人类先验和人类智能对数据集的理解。
这无疑引出了本质问题,这位“网红”科学家对智能的看法究竟如何?我在这里总结了6个重点供大家讨论,
1. 所谓“智能大爆发”可能存在吗?NO!François认为首先,我们不能孤立地看待“智能”这个东西,它绝不是孤立在天空中的城堡:
 所有我们已知的智能(包括人类智能)都是和这个世界的环境密切交互的,“智能”这个东西更像是集市中的信息交换,他的进展有很多不确定性,一个小市场,外围也许还有多个大市场,周围的环境也复杂多变:
所有我们已知的智能(包括人类智能)都是和这个世界的环境密切交互的,“智能”这个东西更像是集市中的信息交换,他的进展有很多不确定性,一个小市场,外围也许还有多个大市场,周围的环境也复杂多变:

我们人类智能之所以到现在这个阶段,除了为了适应生存生产活动,还要与其它物种竞争,以及一些运气的成分,才让我们变成现在看到的这种“智能”。所以,上下文很重要。
如果说有“超人类的智能大爆发”,那么这个“智能”是如何以这么快的速度适应周围环境和人类以及其他物种竞争的?如果一下子变成超人智能,它又是如何像爱因斯坦那样寻找一个宏大的问题的答案?至少从David的直觉,我赞同François。我认为这种突破是缓慢的信息交互的产物,不是可以“爆发”产生的,但可以缓慢到达某个阶段。
2. 智能是线性增长的。这也许是François最著名的论断,David之前就听过。 他的解释也很有意思,他不否认当一个产业兴起时,资源的分配是爆炸增长的,这就是我们在日常生活中的感觉(几十年前的互联网泡沫,工业革命,信息化革命,AI浪潮等等)。但是,科学本身的发展是线性的,下图是历年来物理学发展突破的评分图:
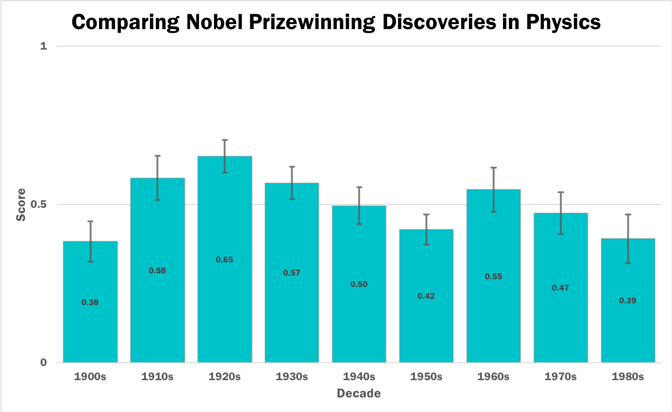
图中每10年的物理学发展程度,大都是平缓持平的,没有巨大波动。因此如果把人类总体的智慧做一个大智能体, 继续阅读探究“网红科学家”眼中的”智能“:Keras作者François Chollet谈AI,以及David的一些想法