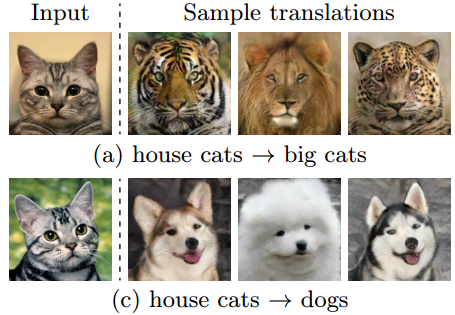
召回率和准确率就像你去赌场要同时带着“票子”和“运气” — David 9
在机器学习面试中,经常会问道“召回率”和“准确率”的区别 。 其实,就像你去赌场下注一样,如果你“票子”很多,可以把钱分摊在不同的赌注上,总有一个赌注会猜对,当你猜对了,就是一次“召回”了; 而“准确率”不关注你下多少注,好似你在赌场碰“运气”,下注越多,越能看出你今天的“运气”。
因此,你猜的次数越多自然有较大的召回,当然最好的情况是,你猜测很少次数就能召回所有。
计算召回率(Recall) 和 精确率(Precision) 时,人们一般会先搬出TP(True positive),TN(True negative),FP(False positive),FN(False negative )的概念:
Condition: A Not A
Test says “A” True positive | False positive
----------------------------------
Test says “Not A” False negative | True negative
然后给出公式:
召回率 Recall = TP / (TP + FN)
准确率 Precision = TP / (TP + FP)
事实上,不用硬背公式。两者的抽样方式就很不同: 召回率的抽样是每次取同一标签中的一个样本,如果预测正确就计一分;准确率的抽样是每次取你已预测为同一类别的一个样本,如果预测正确就计一分。这里一个关键点是:召回率是从数据集的同一标签的样本抽样;而准确率是从已经预测为同一类别的样本抽样。召回率和准确率都可以只针对一个类别。 继续阅读David9的普及贴:机器视觉中的平均精度(AP), 平均精度均值(mAP), 召回率(Recall), 精确率(Precision), TP,TN,FP,FN