如果大脑中的每个神经元都代表一些训练参数,那么,我们在不断的学习过程中,现有的神经元够用吗?大脑是如何优化参数效率的? — David 9
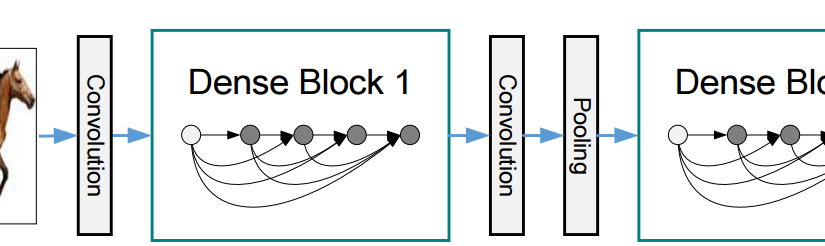
这届CVPR上的两篇最佳论文中, David 9更欣赏康奈尔大学和清华大学的密集连接卷积网络DenseNet(Densely Connected Convolutional Networks) , 内容有料,工作踏实 !我们在之前文章就提到,模型泛化能力的提高不是一些普通的Tricks决定的,更多地来源于模型本身的结构。
CNN发展至今,人们从热衷于探索隐式正则方法(Dropout, Batch normalization等等),到现在开始逐渐关注模型本身结构的创新。这是一个好现象。
密集连接卷积网络DenseNet正是试图把跳层连接做到极致的一种结构创新:
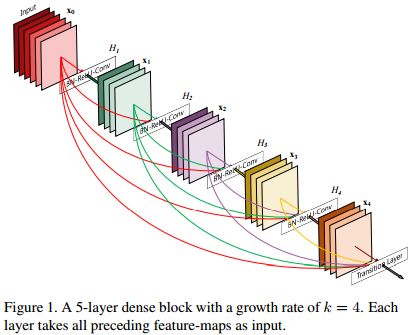
跳层连接方法是对中间层输出特征图信息的探索,之前的ResNets和Highway Networks都曾使用,把前层的输出特征图信息直接传递到后面的一些层,可以有效地提高信息传递效率和信息复用效率。 继续阅读CVPR 2017论文精选#2 密集连接的卷积网络DenseNet(Best paper award 最佳论文奖)