分布式架构就像哈姆雷特,一千个人眼中有一千种分布式方式 — David 9
对于机器学习模型,分布式大致分两类:模型分布式和数据分布式:
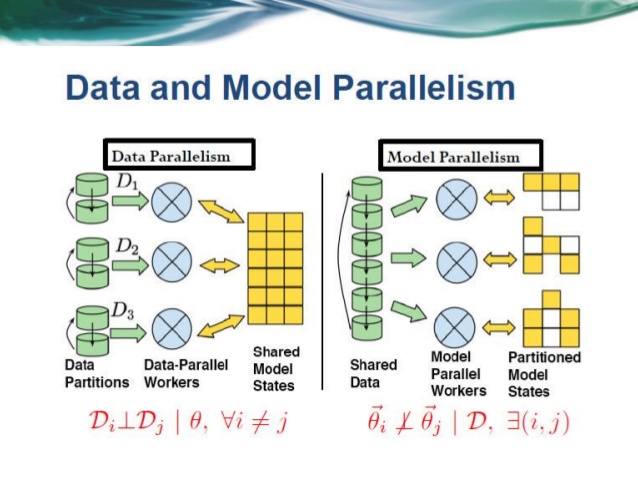 模型分布式非常复杂和灵活, 它把整个机器学习模型分割,分散在多个节点上,在每个节点上计算模型的各个部分, 最后把结果拼接起来。如果你造了一个并行性很高的深度网络,比如这个,那就更棒了。你只要在每个节点上,计算不同的层,最后把各个层的异步结果通过较为精妙的方式汇总起来。
模型分布式非常复杂和灵活, 它把整个机器学习模型分割,分散在多个节点上,在每个节点上计算模型的各个部分, 最后把结果拼接起来。如果你造了一个并行性很高的深度网络,比如这个,那就更棒了。你只要在每个节点上,计算不同的层,最后把各个层的异步结果通过较为精妙的方式汇总起来。
而我们今天要手把手教大家的是数据分布式。模型把数据拷贝到多个节点上, 每次算Epoch迭代的时候,每个节点对于一个batch的梯度都会有一个计算值,一个batch结束后,所有节点把梯度值汇总起来(ps参数服务器的任务就是汇总所有参数更新),从而进行更新。这就会导致每个batch的计算都比非分布式方法精准。相对非分布式,并行方法下,同样的迭代次数,收敛较快。 继续阅读TensorFlow手把手入门之分布式TensorFlow — 3个关键点,把你的TensorFlow代码重构为分布式!