机器视觉是一场科学家与像素之间的游戏 — David 9
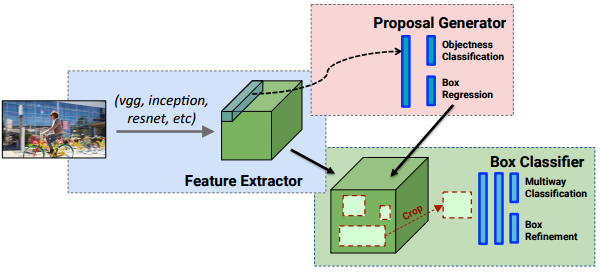
上一期,我们已经介绍了R-CNN系列目标检测方法(R-CNN, Fast R-CNN, Faster R-CNN)。事实上,R-CNN系列算法看图片做目标检测,都是需要“看两眼”的. 即,第一眼 做 “region proposals”获得所有候选目标框,第二眼 对所有候选框做“Box Classifier候选框分类”才能完成目标检测:
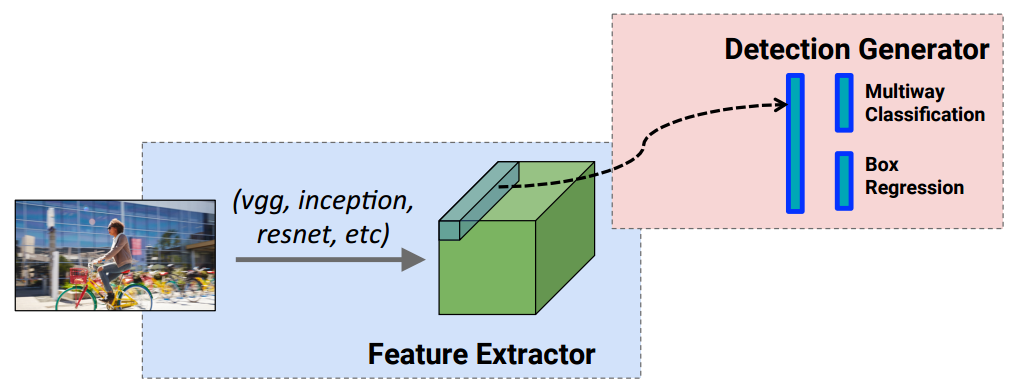
事实上“第一眼”是挺费时间的,可否看一眼就能得到最后的目标检测结果?达到实时检测的可能? 答案是肯定的,这也是我们要讲YOLO的由来 — You only look once !
YOLO能够做到在输出中同时包含图片bounding box(检测框)的分类信息和位置信息:
理论上,每次卷积后,信息是没有损失的(前提是没有使用pooling层),只是信息更“深”了(人类无法看懂, 但是机器可以)。
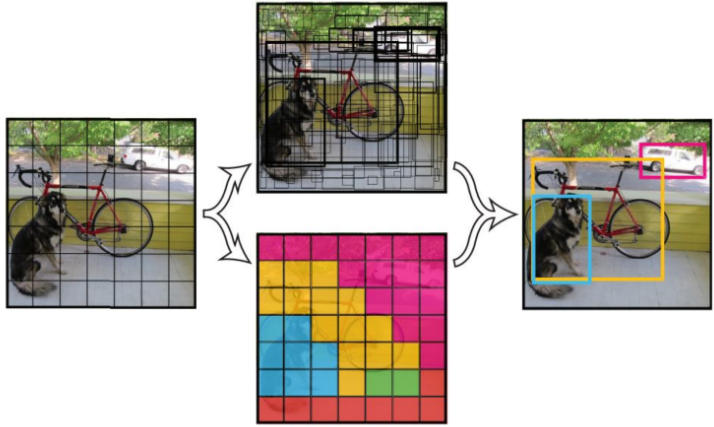
试着想象这样的情况, 我们用1*1的卷积小方格去卷积一张7*7的图片, 试图目标检测:

显然, 卷积的输出也是7*7:
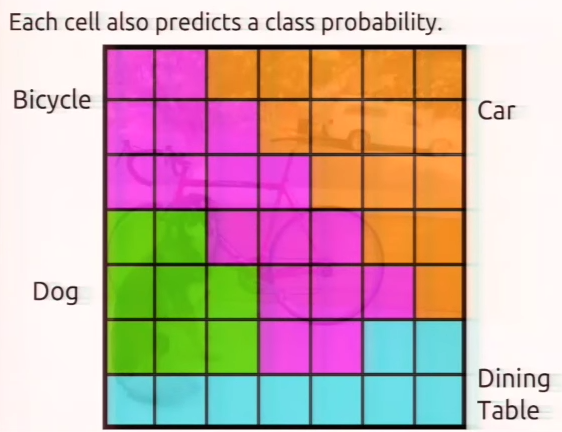 但是我们可以做一些神奇的事情, 卷积窗口filter出了被窗口过滤后的类别 ! 我们可以为每个过滤后的小窗口(cell)赋予一个类别, 比如, 是自行车Bicycle的类别中的像素过滤为上图紫色. 当然, 也有可能一些小方格输入多个类别, 比如也可能属于猫同时属于自行车的识别中.
但是我们可以做一些神奇的事情, 卷积窗口filter出了被窗口过滤后的类别 ! 我们可以为每个过滤后的小窗口(cell)赋予一个类别, 比如, 是自行车Bicycle的类别中的像素过滤为上图紫色. 当然, 也有可能一些小方格输入多个类别, 比如也可能属于猫同时属于自行车的识别中.
这样, 我们自然地在卷积的同时, 把类别信息和位置信息同时包含进去了.
上述是便于理解的例子, 大家不要真的以为YOLO第一层卷积就使用了1*1的卷积窗口 !
事实上, 原理是这样但每一层窗口是大一点3*3的:

我们来仔细看看最后一层发生了什么:
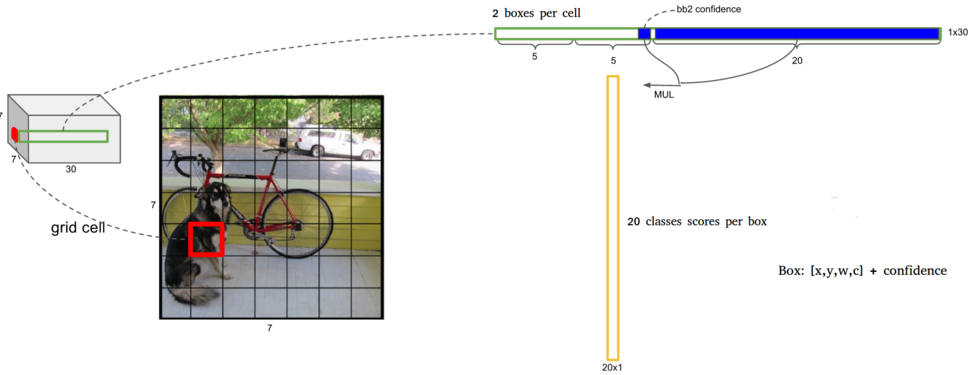
中间是最后一层需要卷积的图片(实际上是人类无法看懂的卷积通道图片). 左边是卷积示意图, 其中细细的一条是卷积输出的通道包含的信息, 放大后, 可看到右边通道的信息包含box的候选位置信息, 5位是box, 两5位代表支持一个卷积窗口同时包含在两个识别物体框中. 之后的蓝色位数代表该位置为某个类别物体的置信度. 两个相乘MUL, 就是每个位置对每个类别置信度的信息.
理解了YOLO最主要的卷积方法之后,我们头脑中还要有个概念,就是YOLO不仅仅只有独特的卷积方法,还有对候选框交集(Intersect over Union (IoU))的处理和非极大值抑制算法(Non-Maxima Suppresion) . 总体上YOLO框架 如下:

评价真实目标检测框和预测检测框的差异非常简单,即:
检测框交叉面积 / 检测框的并集面积
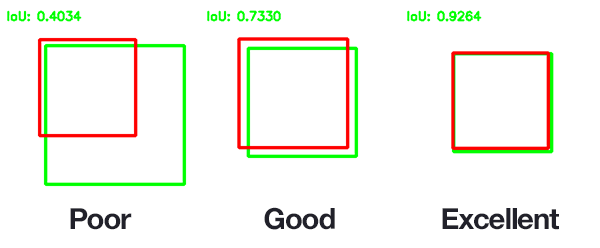 最后,卷积层的输出可能是对同一个检测目标的许多个检测框,我们有高效的非极大值抑制算法来选择最好的检测框:
最后,卷积层的输出可能是对同一个检测目标的许多个检测框,我们有高效的非极大值抑制算法来选择最好的检测框:

最后, YOLO也是有自身缺陷的:
- YOLO对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
参考文献:
- https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/single-shot-detectors/yolo.html
- http://blog.csdn.net/hx921123/article/details/55802795
- https://zhuanlan.zhihu.com/p/25045711?refer=shanren7
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
yolo初始版本最后一层全连接层回归7x7x30的tensor之前,还经过了一个额外的全连接层将整幅图像变为4096维的向量,因此,并非是您所想象的用1×1的滤波器卷积7×7的feature map。
David 9想着重说一下:文章中1*1的例子只是便于大家理解yolo提取信息的方式。实际上,yolo架构中大量卷积窗口是3*3的(见文章中的图),并不是1*1。
大家千万不要以为yolo大量使用了1*1卷积提取信息。