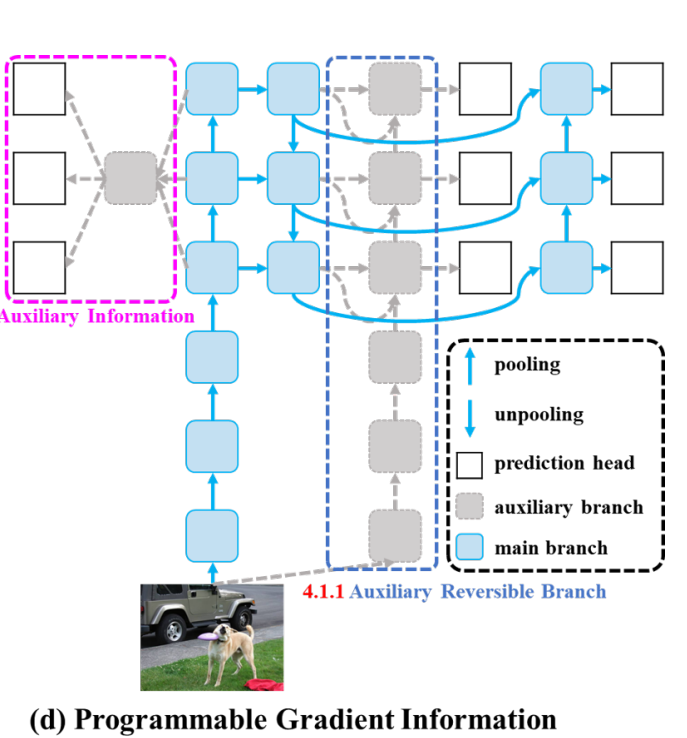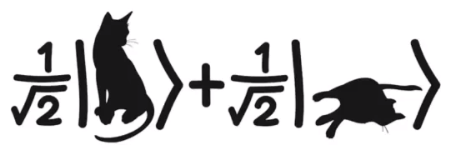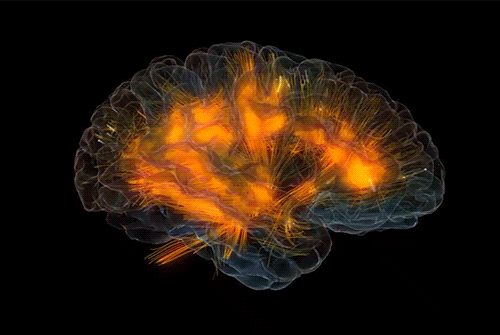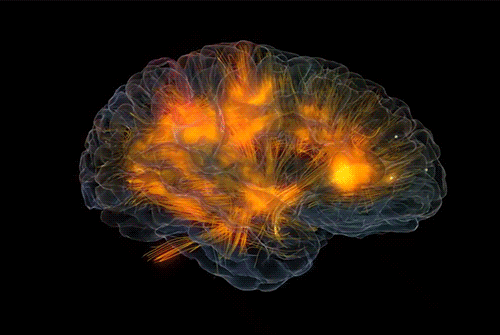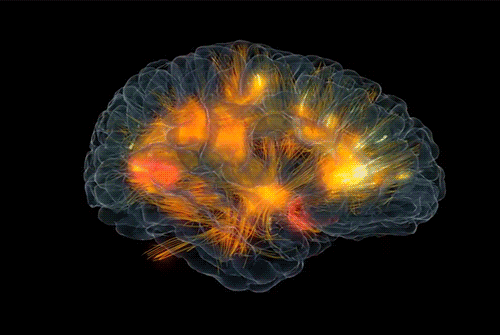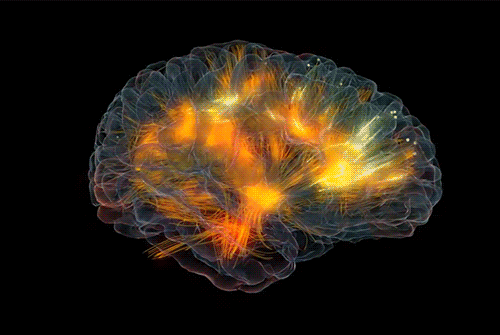
我们就是梦幻所用的材料,
一场睡梦环抱了短促的人生 —— 威廉·莎士比亚
智能体,特别是强协作的智能体,总是有许多相似之处,例如,我们总是可以把智能体看成客体,Ta是形成智能行为所需的“智能材料”, 而其主体是更底层的物质。
人类社会作为一个大型智能体,正在不断扩充自身物理和意识的边界,但是其主体——单个人类,是智能体不断运作的源泉,个体人类之间的连接方式(或强弱),或是人群聚集的模式,或是单个个体能力和功能上的变化,都会导致人类社会这个大型智能体的改变。
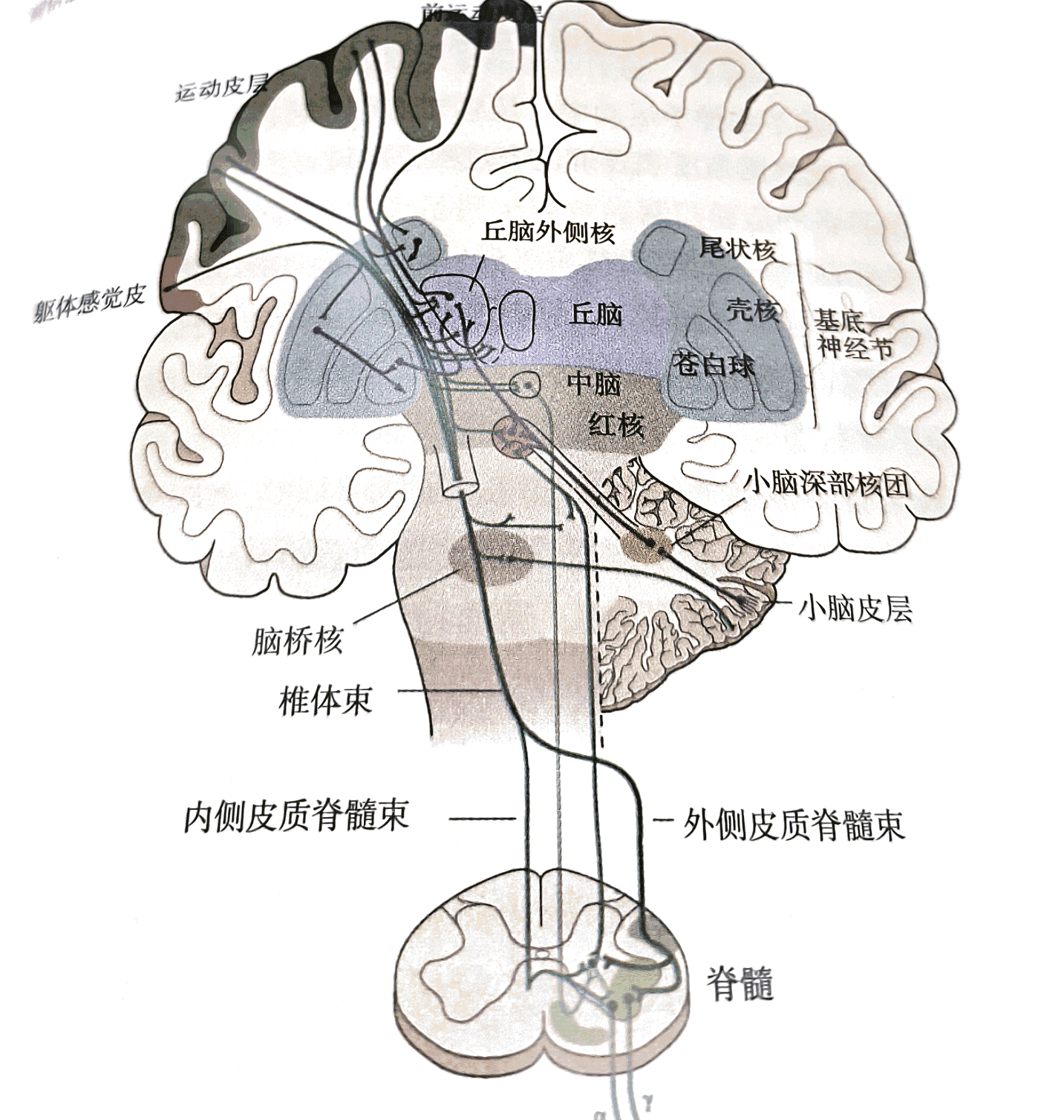
同样,对于我们单个人体自身,身体内部的基因或者神经元的选择,决定了我们的智能形态,我们的身体更像是基因或者神经元进行“智能实现”的材料,即使假设我们有自主意识,你会发现从一个拥有运动天赋的人转变为一个具有科学天赋的人可能会多么困难。 基因或者更深层次的物质已经为其所拥有的材料作出了选择,比如 ,虽然小脑体积只占整个脑的十分之一,但它却包含整个脑的一半以上的神经元: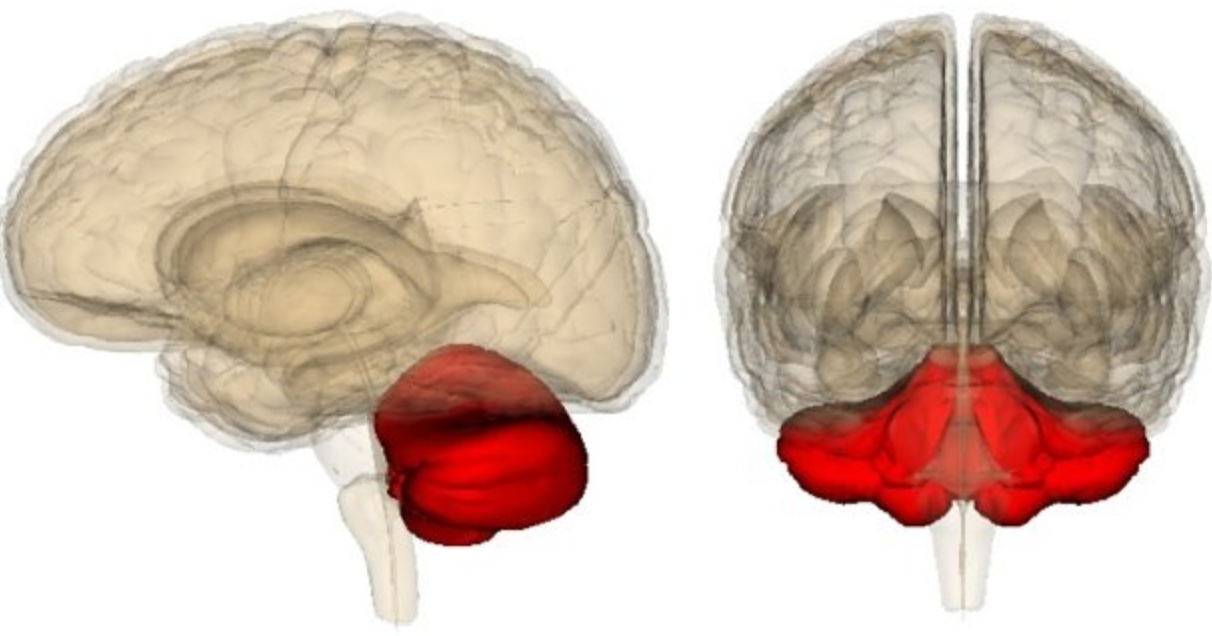
如果每个人出生后的神经元是固定数量的,这些神经元的分布,组织和分配行为,是如何做到在混沌的世界中有序运作的,是研究类脑智能最有意思的问题。
这里需要指出的是,上面指出的“材料”不仅仅是智能体自身内部的自由资源,还有可以感知到的外部的自由资源。因此, 继续阅读我们和我们的梦幻:对类脑智能的一些看法(一) ,Brain-inspired Intelligence