
狙击手在放大倍焦前已经经历了大量的小目标训练,这样看似乎是RPN做的好 — David 9
之前在讲SSD时我们聊过SSD的目标检测是如何提高多尺度(较大或较小)物体检测率的。我们来回顾一下,首先,较大的卷积窗口可以卷积后看到较大的物体, 反之只能看到较小的图片. 想象用1*1的最小卷积窗口, 最后卷积的图片粒度和输入图片粒度一模一样. 但是如果用图片长*宽 的卷积窗口, 只能编码出一个大粒度的输出特征.
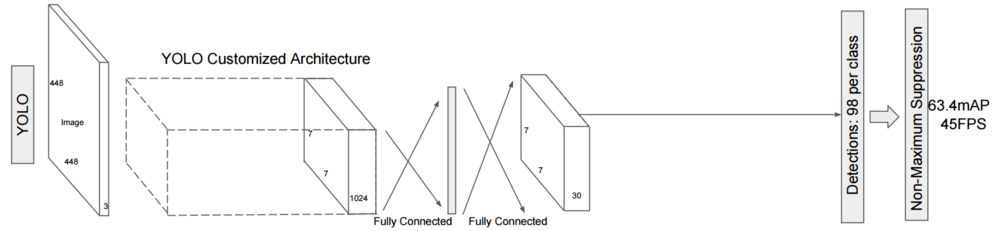
对于yolov1,每层使用同样大小的卷积窗口, 识别超大物体或者超小物体就变得无能为力(最后一层的输出特征图是固定7*7):
而SSD就更进一步,最后一层的检测是由之前多个尺度(Multi-Scale)的特征图共同生成的:
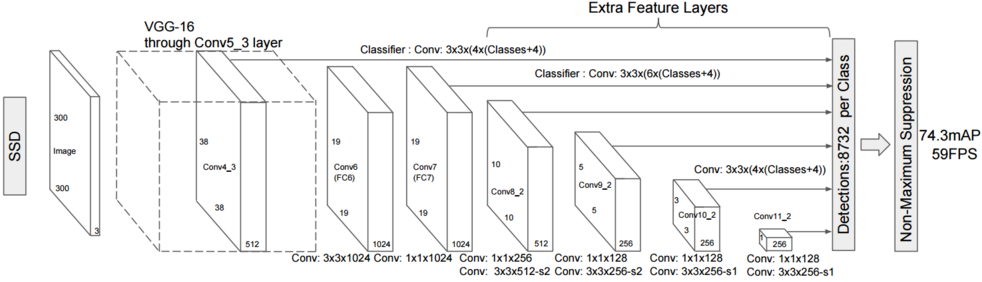
这样SSD在计算复杂度允许的情况下,在多尺度物体的检测上有所提高。但是SSD也有明显缺陷,其最后几层的所谓“多尺度”是有限的(如上图特征图尺寸越小,可以识别的物体越大)。对于极小的目标识别,SSD就显得无能为力了,

假设“风筝”只占原始图片的几十个像素,SSD的高层特征图已经无法捕捉如此小的物体。
为了解决上述问题facebook的老兄们开发出了FPN(特征金字塔网络),这种网络不是一味地进行下采样提取语义特征去识别物体,而是从顶层(自上而下)的每一层都进行上采样获取更准确的像素位置信息(有些类似残差网络的跳层连接):
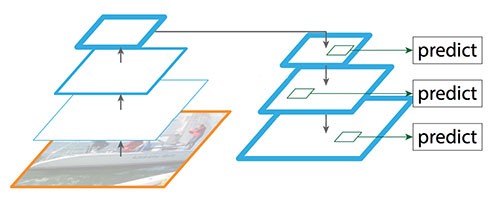
我们知道卷积操作虽然能高效地向上提取语义,但是也存在像素错位的问题
The following two tabs change content below.




David 9
邮箱:yanchao727@gmail.com
微信: david9ml
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024